确定新产品应使用何种类型的无线技术可能是一项艰巨的任务。 目前不仅有大量的无线技术可用,而且它也是一个不断推出新技术的移动目标。
为了简化为您的产品选择最佳无线技术的过程,我已根据功能,数据速度和操作范围将各种无线技术组织成一个组。
本文最初发布于PredictableDesigns.com。 下载他们的免费备忘单 15步骤开发您的新电子硬件产品 。
根据产品的预期功能,您可以相对简单地立即确定需要考虑的技术组。
例如,如果您需要两个相隔30英尺的设备来传输少量数据,那么使用任何长距离或高速无线技术都没有意义。
话虽如此,我建议您阅读整篇文章,无论您的产品具体需求如何,因为您可以大致了解所有可用的无线技术。
注意: 这是一篇冗长,非常详细的文章,所以这里有一个 免费的PDF版本 ,便于阅读和将来参考。 您还将获得一个比较各种无线技术的Excel电子表格。
点对点技术
点对点 简单地表示两个设备连接在一起以进行直接通信。 通常只有两个设备可以参与对等连接。
在下一节中,我将讨论所谓的网状网络技术,它们允许许多设备互相连接。
蓝牙经典
最着名的点对点无线技术是 蓝牙 。 将手机连接到蓝牙扬声器时,蓝牙扬声器是手机和扬声器之间的点对点无线连接。
蓝牙主导着点对点流媒体音频应用,例如这款蓝牙耳机。
由于相对较短的工作范围,蓝牙功耗相当低。 它比WiFi消耗更少的功率,比蜂窝技术少得多,但仍远远超过蓝牙低功耗或Zigbee等技术。
WiFi Direct
每个人都知道WiFi,但很少有人听说过 WiFi Direct 。 即使几乎所有手机和平板电脑都支持它,情况也是如此。 与蓝牙一样,但与传统WiFi不同,WiFi Direct是一种点对点无线技术。
您可能已经知道,传统的WiFi设置了一个允许许多设备连接到它的接入点。 但是,如果您想在没有接入点开销的情况下将数据直接从一个设备传输到另一个设备,该怎么办? 这就是WiFi Direct发挥作用的地方。
WiFi Direct使用与传统WiFi相同的基本技术。 它使用相同的频率并提供类似的带宽和速度。 但是,它不需要接入点,允许两个设备具有类似于蓝牙的直接连接。
WiFi Direct相对于蓝牙的优势主要是传输速度更快。 事实上,WiFi Direct比蓝牙快一百倍。 虽然这个速度是有代价的,但价格主要是更高的功耗。
近场通信
近场通信(NFC)与本文中讨论的其他无线技术根本不同。 NFC使用在两个线圈之间共享的电磁场进行通信,而所有其他无线技术发射无线电波。
由于NFC通过两个电磁耦合在一起的线圈进行通信,因此工作范围仅为一英寸或两英寸。 两个耦合线圈基本上形成具有空气芯的变压器。
NFC 最常见的用途 是非接触式支付系统。 虽然支付数据当然是加密的,但NFC的极短操作范围也有助于消除附近其他人破解交易的可能性。
NFC允许使用无源NFC标签。 在这种情况下,被动意味着没有电源。 相反,无源标签由NFC读取器设备的电磁场供电。 通信和功率传输都发生在两个耦合线圈之间。
无源标签的优点是它们简单,便宜,小巧,并且几乎无限期,因为没有电池。 还提供有源标签,其中包括电池。
作为旁注,无线充电,通过将设备放置在充电垫上为设备充电,也可以利用两个耦合线圈之间的相同功率传输现象。
低功耗/短程/低数据网格技术
创建低功耗,低数据网络有四种常用技术:蓝牙低功耗,Zigbee,Z-Wave和6LoWPAN。
如果您的产品是电池供电的,并且需要在短距离内发送相对较少的数据,那么这四种技术中的一种可能是最佳解决方案。
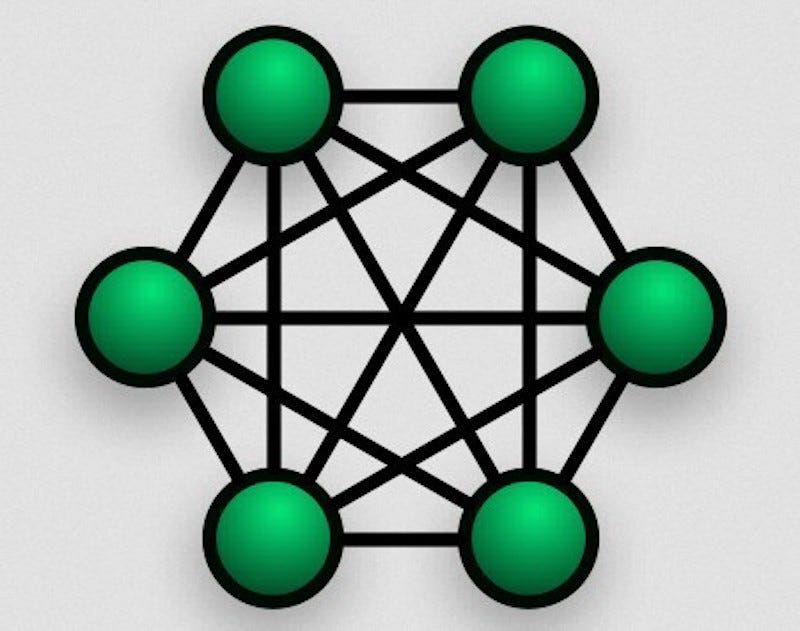
所有这四种技术支持的关键特性称为网状网络,有时也称为 多对多 网络 。
网状网络允许多对多通信。
通常,要将数据从设备A发送到设备C,您必须在设备A和设备C之间形成直接链接。对于蓝牙和WiFi Direct等对等技术就是这种情况。
但是通过网状网络,您可以 通过 设备B将数据从设备A发送到设备C.数据从设备A发送到设备B,设备B然后将数据中继到设备C.这允许您创建庞大的互连设备网络可以覆盖功率极低的大面积区域。
例如,假设您有26个标记为A到Z的设备,这些设备在每个设备之间以一百英尺的距离间隔开。 通常情况下,如果您想将数据从设备A一直发送到距离2500英尺远的设备Z,您需要一台功率相当大的发射机。 这需要具有大电池的产品。
但是使用网状网络,您可以将数据从设备A中继到设备B,再到设备C等,直到设备Z.没有一台设备必须传输超过一百英尺的数据,因此需要的功率由每个设备都小得多。
网状网络可以打开很多非常有趣的应用程序。
蓝牙低功耗(BLE)
蓝牙低功耗不仅仅是蓝牙经典的低能耗版本。 事实上,它的应用程序与普通蓝牙完全不同。
蓝牙LE可能是我帮助开发的产品最常见的无线功能类型。 它设计用于在相当不频繁的基础上传输/接收少量数据,同时消耗极低的功率。
BLE有许多应用,但最常见的一种是传输传感器数据。 每分钟测量一次温度的传感器设备,或者每10分钟记录并传输其位置的GPS设备就是一些例子。
在许多情况下,蓝牙LE产品仅使用小型纽扣电池供电。 如果数据不经常发送,则从纽扣电池运行的BLE设备可能具有一年或更长的电池寿命。
手机和平板电脑广泛支持蓝牙LE,使其成为将产品连接到移动应用的理想解决方案。 它还支持高达1Mbps的下降传输速度(经典蓝牙可以达到2-3 Mbps)。
与本节中讨论的所有技术一样,BLE支持网状网络。 实际上,它允许最多32,767个设备的网状网络!
除非您有充分的理由选择我在本节中讨论的其他技术(Zigbee,Z-Wave和6LoWPAN),否则我强烈建议您使用蓝牙LE。 它是最简单的无线技术,功耗极低,是最受支持的技术。
BLE,Zigbee,Z-Wave和6LoWPAN都是智能家居应用的潜在解决方案。
Zigbee是另一种短距离网络技术,在许多方面类似于具有类似应用的蓝牙LE。 它使用相同的2.4 GHz载波频率,功耗极低,在相似范围内运行,并提供网状网络。
实际上,Zigbee网状网络可以包含多达65,000个设备,这是蓝牙LE可以支持的两倍。 但是,我还没有看到推动任何限制的应用程序。
Zigbee 主要用于家庭自动化应用,如智能照明,智能恒温器和家庭能源监控。 它还常用于工业自动化,智能仪表和安全系统。
Z-波
Z-Wave是一种专有无线技术(由Silicon Labs于2018年收购),主要与家庭自动化市场中的Zigbee和BLE竞争。
与使用流行的2.4 GHz频段的BLE和Zigbee不同,Z-Wave使用的是低于1GHz的频段。 如果您希望在全球范围内销售产品,则许多国家/地区的确切频段会有所不同,这可能会导 在美国,Z-Wave工作在908 MHz,而在欧洲,它使用868 MHz。 其他国家和地区使用从865 MHz到921 MHz的所有内容。
载波频率较低有两个显着优点:增加范围和减少干扰。 较低频率的无线电波进一步传播。 BLE和Zigbee使用的2.4 GHz频段也用于WiFi,Bluetooth Classic甚至是微波炉,因此存在很多干扰的可能性。
Z-Wave使用的频段往往不那么拥挤。 较低载波频率的缺点是较低的数据传输速度,最终比蓝牙LE慢近10倍。
Z-Wave 支持最多232个设备的小型网状网络,这对大多数应用来说已经足够了。
6LoWPAN的
6LoWPAN是一种奇怪命名的技术,它结合了两种不同的首字母缩略词。 6指的是Internet协议(IP)版本6,而LoWPAN指的是低功耗无线个人局域网。 我知道,这个名字很敏捷。
6LoWPAN基本上是Zigbee的新竞争者。 主要区别在于6LoWPAN是基于IP的网络,如WiFi。 与Zigbee和Z-Wave一样,6LoWPAN主要用于家庭自动化应用和智能电表。
局域网(LAN)技术
WiFi,甚至可能比蓝牙更多,可能几乎不需要介绍。 如果您的产品需要访问互联网,并且将始终在WiFi接入点附近使用,那么WiFi就是答案。 由于其适度的覆盖区域,WiFi被称为局域网(LAN)技术。
WiFi快速,便宜,易于实施,具有良好的操作范围,并且可以广泛使用。 至少对于移动产品而言,WiFi的最大缺点是功耗。 由于功耗较高 , 如果您不需要WiFi提供的性能 , 通常最好使用其他无线技术。
远程蜂窝技术
如果您的产品需要访问云,但它不会始终位于WiFi接入点附近,那么您的产品可能需要蜂窝无线电进行长途通信。
您的产品所需的确切蜂窝技术类型取决于您传输数据的速度,以及产品销售地点的较小程度。
GSM / GPRS
长期以来,GSM(全球移动通信系统)与GPRS(通用分组无线业务)相结合进行数据传输已成为不需要大量数据传输的产品最常用的蜂窝技术。 这主要是由于GSM / GPRS硬件的广泛可用性和相对低的硬件成本。
不幸的是,这种情况即将结束。 世界上大多数蜂窝运营商都在 逐步淘汰GSM, 因此他们可以为需要大量数据传输的4G和5G智能手机释放更多带宽。
更不幸的是,至少还没有明显的替代技术。 最可能的选择是将硬件从GSM解决方案升级到LTE蜂窝技术,但随之而来的是价格大幅提升。
LTE
LTE是一种4G蜂窝技术,支持比GSM更快的数据速率。 如果您的产品需要非常快速的蜂窝数据传输速度,那么LTE可能是最佳选择。
但是,如果您的产品并不真正需要这种级别的数据速度,那么您将支付您根本不需要的硬件。 嵌入式GSM模块可以从中国购买,只需几美元,而LTE模块的价格可能超过20美元。 LTE的运营商服务成本也将明显高于GSM。
随着物联网(IoT)设备的大量普及 , 这种技术选择的差距变得更加明显。 不过,这个差距正在被几种不同的新无线技术所填补,我将在下一节讨论。
低功耗远程技术
如果您需要长距离,低数据通信,就像许多物联网产品一样,那么您的技术选择并不像其他应用那样清晰。 这种类型的网络通常被称为LPWAN或低功率广域网。
例如,如果您的产品在远程位置收集天气数据并自动将该数据上传到云,则可能需要LPWAN技术。 正如我已经指出的那样,GSM或LTE蜂窝技术都不适合低数据速率应用。
还有其他无线技术可以解决这个问题,包括LoRa,NB-IoT和LTE-M。 不幸的是,这些都不是广泛支持的全球标准。 这使得许多产品的实施具有挑战性或不可能性,具体取决于它们的销售地点。
LoRa / LoRaWAN
LoRa ( 长距离的 缩写)可以在某些区域进行超过6英里的远距离通信,同时消耗很少的电量。 它是 Semtech 在2012年 收购的专有无线技术 。
LoRa根据操作区域使用各种频带。 在北美,使用915 MHz,在欧洲,频率为868 MHz。 其他区域也可能使用169 MHz和433 MHz。
LoRa指的是底层技术,可以直接用于点对点通信。 LoRaWAN是指上层网络协议。
如果您正在寻找低功耗,长距离,点对点的解决方案,那么LoRa是一个很好的选择。 您通常可以购买比LoRaWAN模块便宜的LoRa模块。
如果您希望您的产品连接到现有的LoRaWAN网络,则需要包含网络层的更昂贵的LoRaWAN模块。 不幸的是,LoRaWAN网络仅在欧洲部分地区提供,而在北美地区则不提供。 这严重限制了LoRaWAN对大多数产品的实用性。
尽管LoRa的设计可以在很大范围内运行,但它并不是可以连接到移动网络的蜂窝技术。 这使得它更简单,实施起来更便宜,但它的应用程序是有限的。
例如,如果您的产品需要远程访问云,那么您还需要提供LoRa网关设备以连接到Internet。 网关设备连接到互联网,并与任何远程LoRa设备通信。
假设在操作范围内没有LoRa网关,LoRa不为任何单个远程设备提供远程访问云的方法。
NB-IT
与LoRa / LoRaWAN不同,NB-IoT是一种蜂窝技术。 这意味着它更复杂,实施起来更昂贵,并且消耗更多功率。 但是,它提供更高质量的蜂窝连接和直接访问互联网。
NB-IoT仅用于传输非常少量的数据。 NB-IoT 的最大缺点 是可用性有限。 目前还没有美国运营商支持它,目前它只在欧洲进行测试。 但它有望在2019年的某个时候在美国推出。
这项技术现在可能无法在您的产品中实施,但在未来几年内它将变得更加实用。
LTE-M
如果您的产品需要具有比LoRa或NB-IoT支持的更高数据速率的远程蜂窝接入,那么LTE-M可能是您的最佳选择。
LTE-M 是LTE(长期演进)Cat-M1的缩写。 该技术适用于需要直接连接到4G移动网络的物联网设备。 它是LTE蜂窝技术的一个子集,针对从小型电池运行的低数据速率设备进行了优化。
LTE-M在几个关键方面与标准LTE不同。 首先,实施起来更便宜,因为由于带宽更有限,可以使用更简单的芯片。
其次,它针对降低功耗进行了优化,以免快速耗尽小电池。 最后,蜂窝服务成本显着降低,因为您没有使用接近标准LTE所需带宽的任何地方。
结论
选择无线技术的关键是缩小您的要求,以便您可以专注于可行的技术。 所需的工作范围,数据传输速度,功耗和成本是选择无线技术的主要标准。
当然,就像工程中的所有事情一样,你不可能拥有一切。 例如,大的工作范围需要增加功耗。 对于更快的数据速率也是如此。 这些标准之间总会有一些让步。 从来没有一个完美的解决方案。
如果您正在寻找提供长距离,低功耗,高数据速率和低成本的技术,您将永远找不到真实的解决方案。 相反,我建议您优先考虑您的设计标准,并从那里开始缩小您的选择范围。
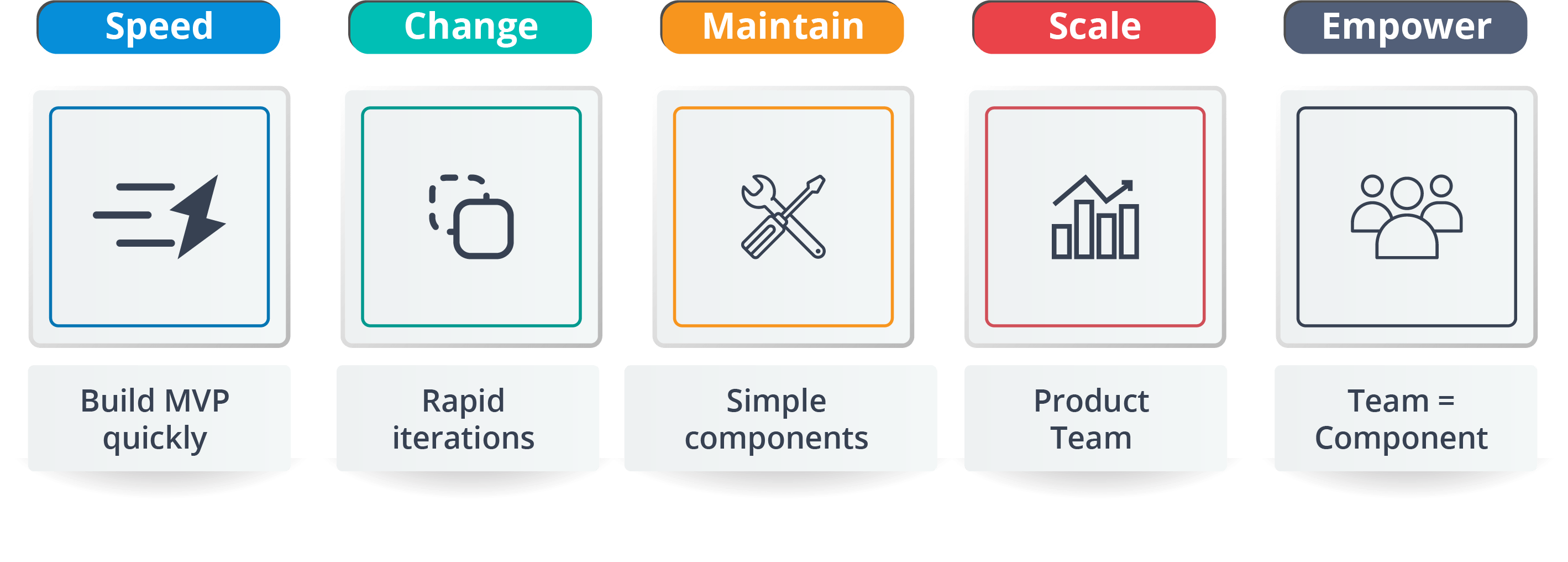



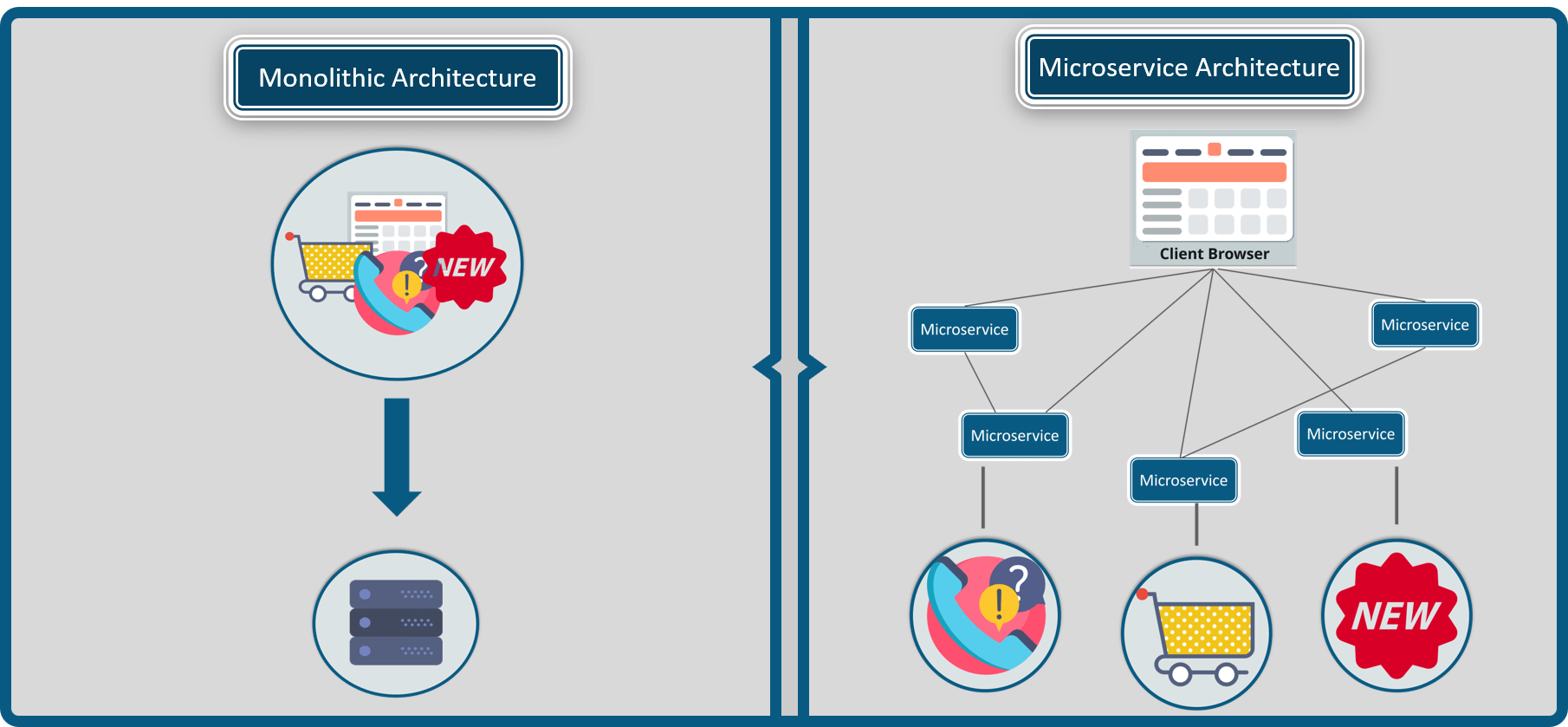
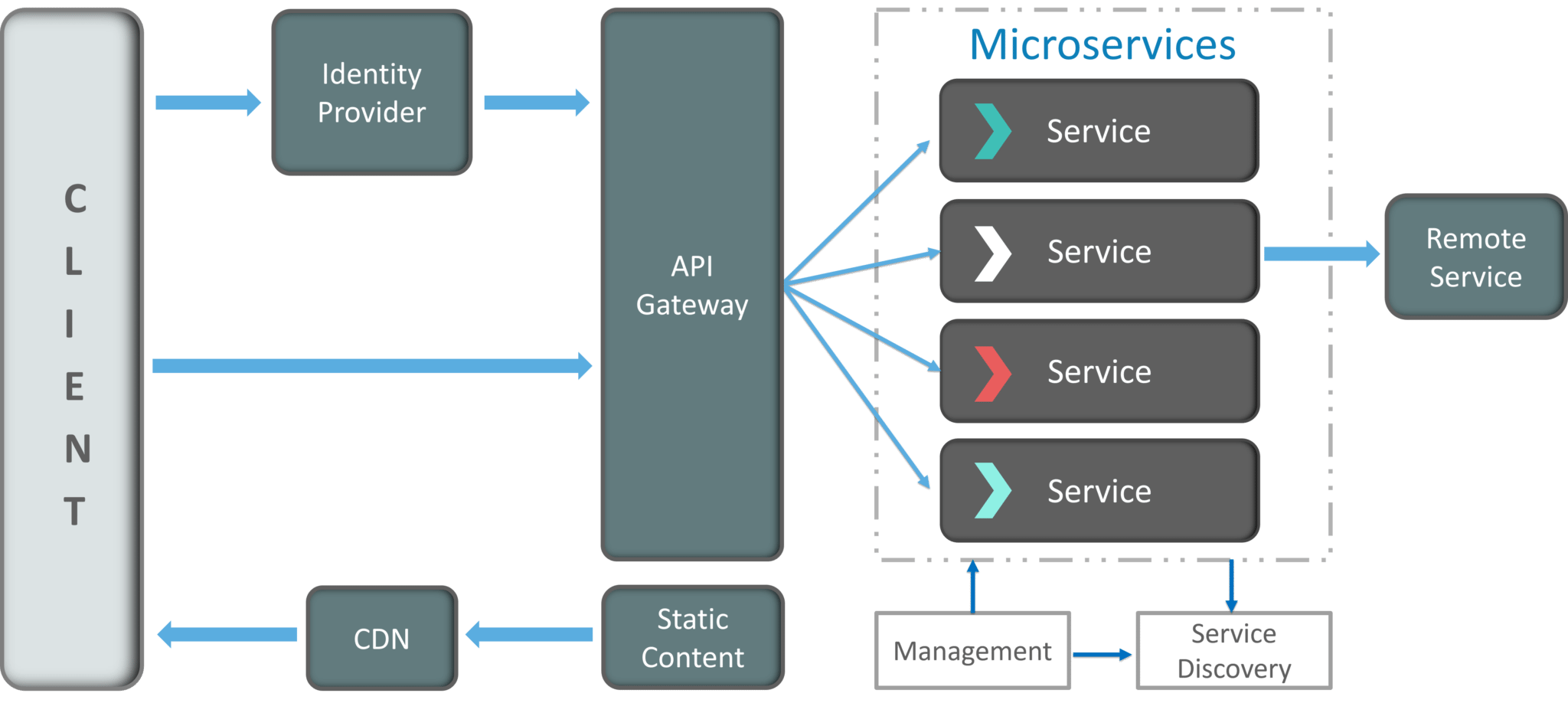

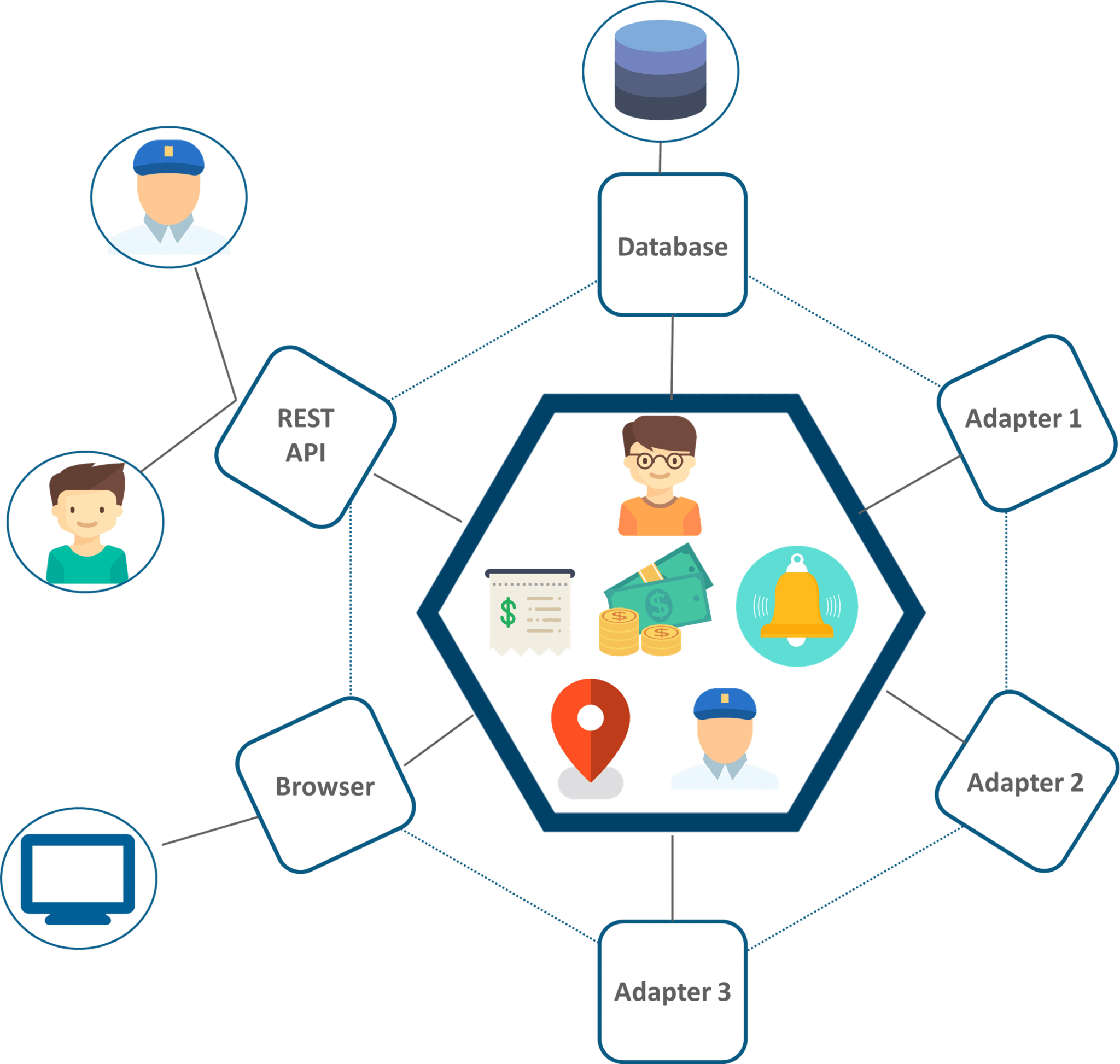
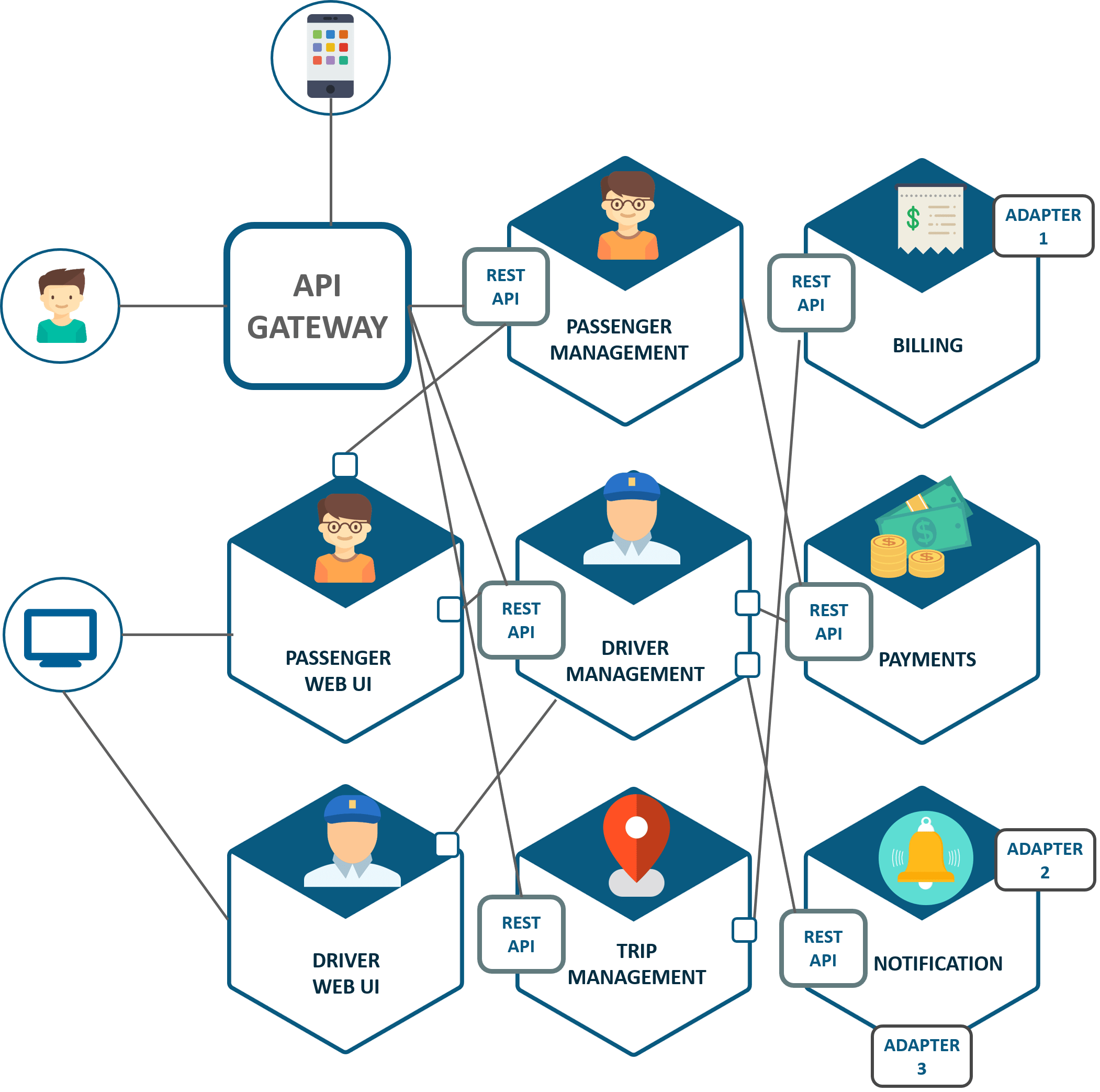







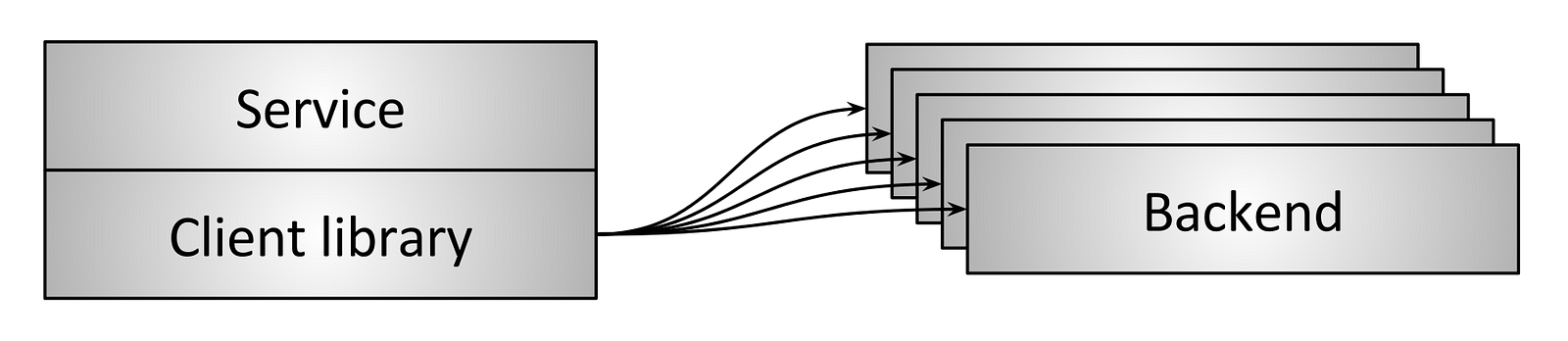
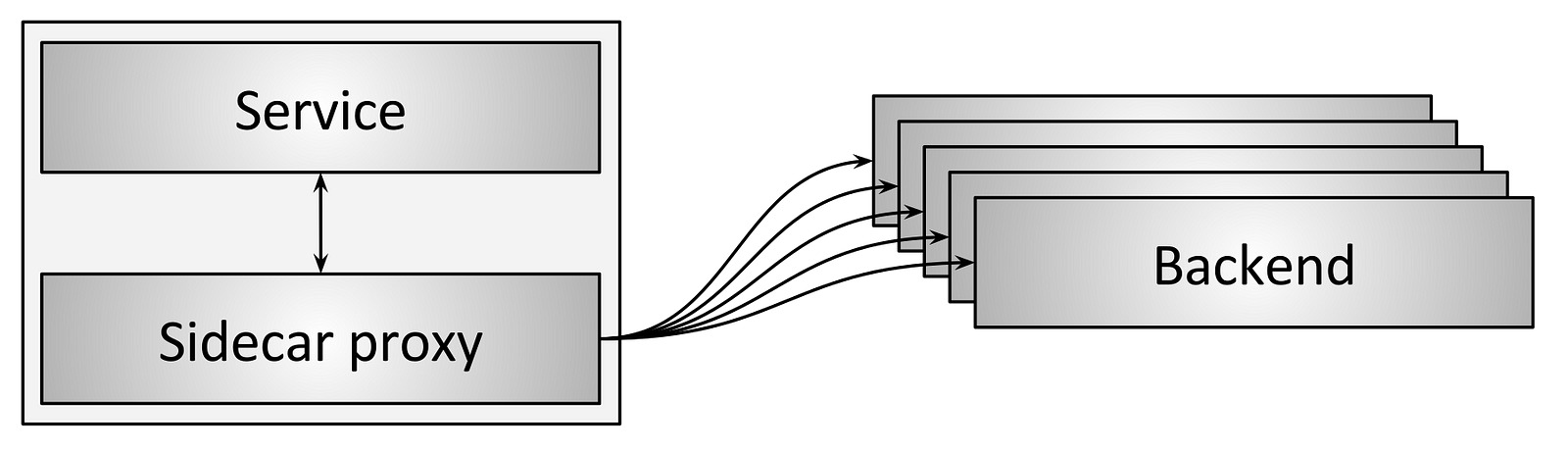
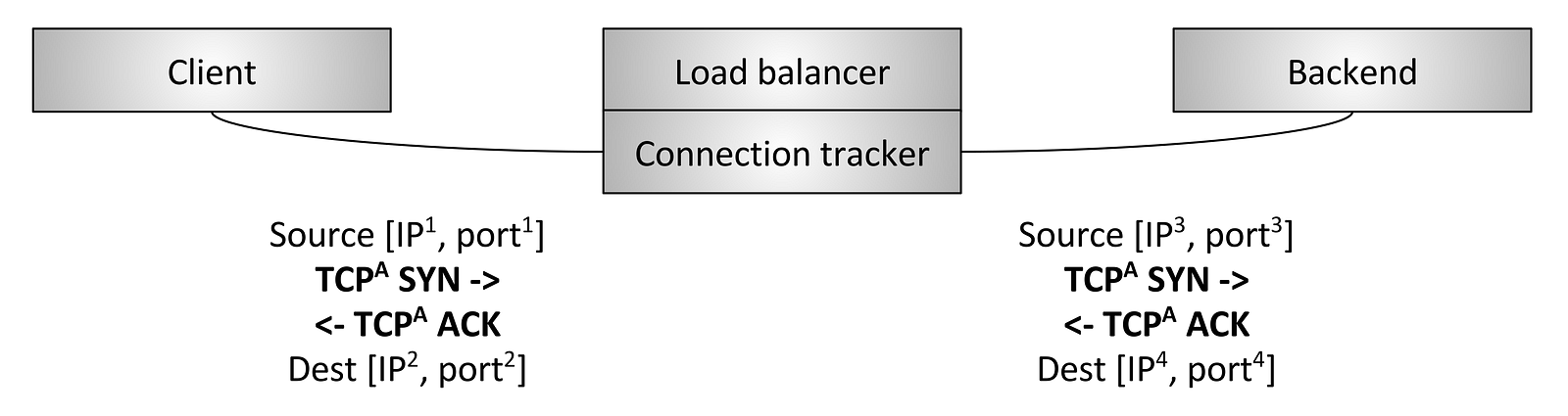



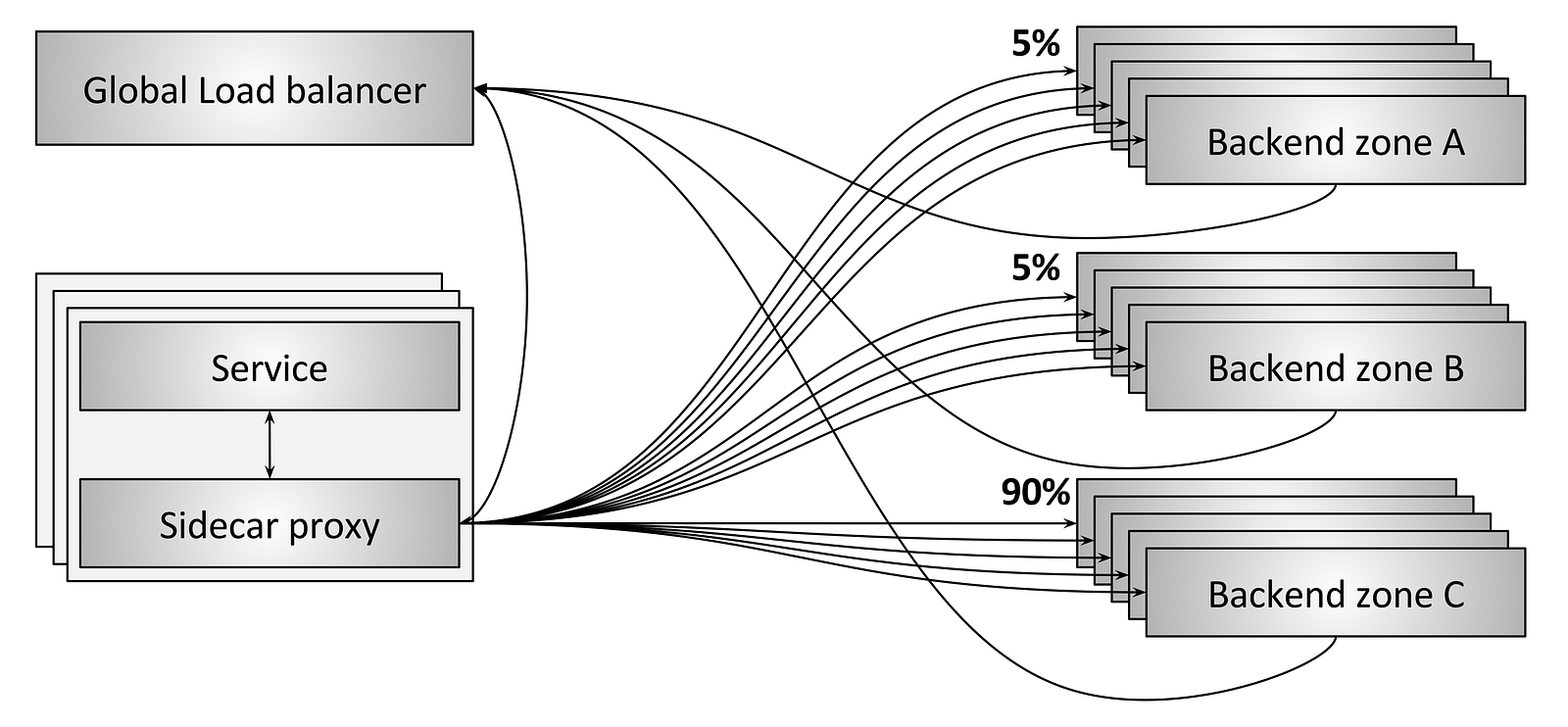
 SRE(Site Reliability Engineer)即站点可靠性工程师,是一种和传统系统管理员以及普通软件工程师有所区别的新型职业类型。从这张表里我们可以看到这三类人群从工作内容、关注点、技能特长和思维特征都不尽相同。
SRE(Site Reliability Engineer)即站点可靠性工程师,是一种和传统系统管理员以及普通软件工程师有所区别的新型职业类型。从这张表里我们可以看到这三类人群从工作内容、关注点、技能特长和思维特征都不尽相同。

 所以,综上所述可以归纳出SRE应该是这样的人。他们关注问题发生的根本原因,更够通过现象看本质,能够将复杂的问题切分成很多部分,这就是我们常说的决策树。再针对这些拆分的部分提出假设,并进行测试。不断深入不同的分支,直到找到根本的原因。他们能够根据大量信息进行归纳和抽象,以便进行深入的调查。基于现有数据和经验进行判断,拒绝主观的臆断。他们不拘泥于现成的“最佳方案”而是根据实际情况追求各方诉求的动态平衡。不但解决眼前出现的问题,还会预见未来的风险和扩展可能性,从而设计出有长远目标的实施方案。最后他们不默守陈规,勇于拥抱变化,不断打破旧的经验,重复造轮。
所以,综上所述可以归纳出SRE应该是这样的人。他们关注问题发生的根本原因,更够通过现象看本质,能够将复杂的问题切分成很多部分,这就是我们常说的决策树。再针对这些拆分的部分提出假设,并进行测试。不断深入不同的分支,直到找到根本的原因。他们能够根据大量信息进行归纳和抽象,以便进行深入的调查。基于现有数据和经验进行判断,拒绝主观的臆断。他们不拘泥于现成的“最佳方案”而是根据实际情况追求各方诉求的动态平衡。不但解决眼前出现的问题,还会预见未来的风险和扩展可能性,从而设计出有长远目标的实施方案。最后他们不默守陈规,勇于拥抱变化,不断打破旧的经验,重复造轮。


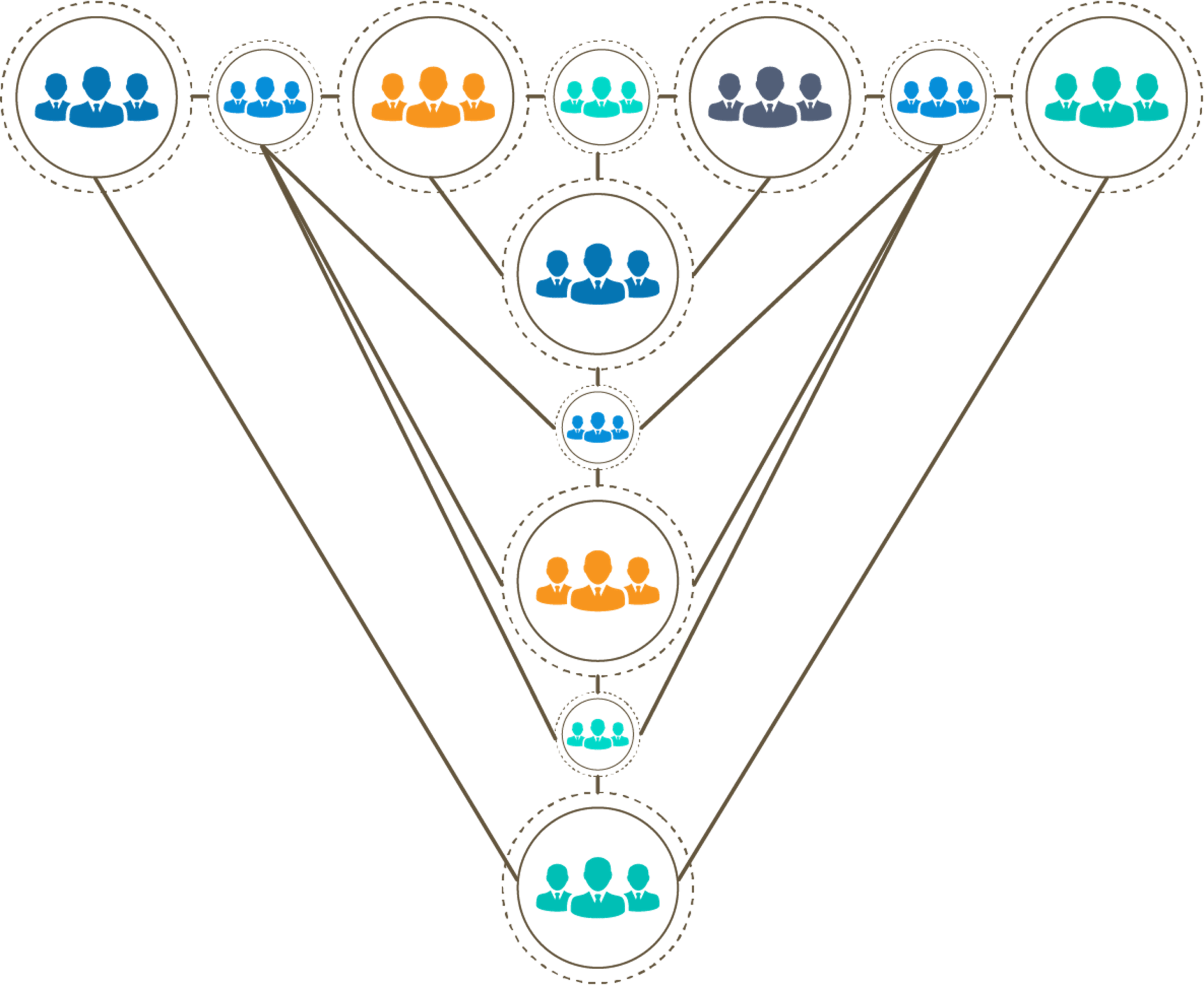
 如何培养一个合格的SRE,Google也积累了一些内容和方法。这张图内包含了SRE团队可以采用的几个培训新员工的最佳实践,同时保证老员工不会落伍。从下面描述的很多个工具中,我们可以从中选择最适合团队的几个来使用。
如何培养一个合格的SRE,Google也积累了一些内容和方法。这张图内包含了SRE团队可以采用的几个培训新员工的最佳实践,同时保证老员工不会落伍。从下面描述的很多个工具中,我们可以从中选择最适合团队的几个来使用。
 故障处理分角色演习
故障处理分角色演习







