本脚本适用环境: 系统支持:CentOS,Debian,Ubuntu 内存要求:≥128M 日期:2016 年 08 月 13 日
关于本脚本: 一键安装 ShadowsocksR 服务端。 请下载与之配套的客户端程序来连接。 (以下客户端只有 Windows 客户端和 Python 版客户端可以使用 SSR 新特性,其他原版客户端只能以兼容的方式连接 SSR 服务器)
默认配置: 服务器端口:自己设定(如不设定,默认为 8989) 客户端端口:1080 密码:自己设定(如不设定,默认为teddysun.com)
客户端下载: Windows / OS X Linux Android / iOS OpenWRT
使用方法: 使用root用户登录,运行以下命令:
wget --no-check-certificate https://raw.githubusercontent.com/teddysun/shadowsocks_install/master/shadowsocksR.sh chmod +x shadowsocksR.sh ./shadowsocksR.sh 2>&1 | tee shadowsocksR.log安装完成后,脚本提示如下:
Congratulations, ShadowsocksR install completed!
Server IP:your_server_ip
Server Port:your_server_port
Password:your_password
Local IP:127.0.0.1
Local Port:1080
Protocol:origin
obfs:plain
Encryption Method:aes-256-cfbWelcome to visit:https://shadowsocks.be/9.html
If you want to change protocol & obfs, reference URL:
https://github.com/breakwa11/shadowsocks-rss/wiki/Server-Setup
Enjoy it!卸载方法:
使用 root 用户登录,运行以下命令:./shadowsocksR.sh uninstall安装完成后即已后台启动 ShadowsocksR ,运行:
/etc/init.d/shadowsocks status可以查看 ShadowsocksR 进程是否已经启动。
本脚本安装完成后,已将 ShadowsocksR 自动加入开机自启动。使用命令:
启动:/etc/init.d/shadowsocks start
停止:/etc/init.d/shadowsocks stop
重启:/etc/init.d/shadowsocks restart
状态:/etc/init.d/shadowsocks status配置文件路径:/etc/shadowsocks.json
日志文件路径:/var/log/shadowsocks.log
代码安装目录:/usr/local/shadowsocks多用户配置 sample:
{ "server":"0.0.0.0", "server_ipv6": "[::]", "local_address":"127.0.0.1", "local_port":1080, "port_password":{ "8989":"password1", "8990":"password2", "8991":"password3" }, "timeout":300, "method":"aes-256-cfb", "protocol": "origin", "protocol_param": "", "obfs": "plain", "obfs_param": "", "redirect": "", "dns_ipv6": false, "fast_open": false, "workers": 1 }如果你想修改配置文件,请参考:
https://github.com/breakwa11/shadowsocks-rss/wiki/Server-Setup更新日志:
2016 年 08 月 13 日:
1、新增多用户配置 sample。注意:如果你新增了端口,也要将该端口从防火墙(iptables 或 firewalld)中打开。2016 年 05 月 12 日:
1、新增在 CentOS 下的防火墙规则设置。
pathinfo配置全局生效的原因
pathinfo配置全局生效的原因后,发现部分目录转发其他服务器代理不能生效,访问的路径还是走pathinfo路径。分析原因,原来是在是否进入要加入一个location / 匹配,否则全部都会到pathinfo。比如我的www.dnsdizhi.com/mptest/public/xxx 变成请求www.dnsdizhi.com/mptest/public/index.php/xxxx
location ~ /mptest/public/ {
proxy_next_upstream http_502 http_504 error timeout invalid_header;
#proxy_cache tmpcache;
#proxy_cache_valid 200 304 1m;
proxy_cache_key $host$uri$is_args$args;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://jingchang-api;
proxy_pass_header Set-Cookie;
expires 10m;
}
location ~ [^/]\.php(/|$)
{
# comment try_files $uri =404; to enable pathinfo
try_files $uri =404;
fastcgi_pass unix:/tmp/php-cgi.sock;
fastcgi_index index.php;
include fastcgi.conf;
set $path_info “”;
set $real_script_name $fastcgi_script_name;
if ($fastcgi_script_name ~ “^(.+?\.php)(/.+)$”) {
set $real_script_name $1;
set $path_info $2;
}
fastcgi_param SCRIPT_FILENAME $document_root$real_script_name;
fastcgi_param SCRIPT_NAME $real_script_name;
fastcgi_param PATH_INFO $path_info;
}
location ~ .*\.(php|php5)?$
{
try_files $uri =404;
fastcgi_pass unix:/tmp/php-cgi.sock;
fastcgi_index index.php;
include fastcgi.conf;
fastcgi_read_timeout 300;
}
location ~ .*\.(gif|jpg|jpeg|png|bmp|swf)$
{
expires 30d;
}
location ~ .*\.(js|css)?$
{
expires 12h;
}
location / {
if (!-e $request_filename)
{
rewrite ^(.*)$ /index.php/$1 last;
break;
}
}
CentOS下shadowsocks-libev一键安装脚本
脚本适用环境:
系统支持:CentOS
内存要求:≥128M
日期:2017 年 02 月 24 日
关于本脚本:
一键安装 libev 版的 Shadowsocks 最新版本。该版本的特点是内存占用小(600k左右),低 CPU 消耗,甚至可以安装在基于 OpenWRT 的路由器上。
友情提示:如果你有问题,请先参考这篇《Shadowsocks Troubleshooting》后再问。
默认配置:
服务器端口:自己设定(如不设定,默认为 8989)
客户端端口:1080
密码:自己设定(如不设定,默认为teddysun.com)
客户端下载:
https://github.com/shadowsocks/shadowsocks-windows/releases
使用方法:
使用root用户登录,运行以下命令:
wget --no-check-certificate -O shadowsocks-libev.sh https://raw.githubusercontent.com/teddysun/shadowsocks_install/master/shadowsocks-libev.sh chmod +x shadowsocks-libev.sh ./shadowsocks-libev.sh 2>&1 | tee shadowsocks-libev.log
安装完成后,脚本提示如下:
Congratulations, Shadowsocks-libev install completed! Your Server IP:your_server_ip Your Server Port:your_server_port Your Password:your_password Your Local IP:127.0.0.1 Your Local Port:1080 Your Encryption Method:aes-256-cfb Welcome to visit:https://teddysun.com/357.html Enjoy it!
卸载方法:
使用 root 用户登录,运行以下命令:
./shadowsocks-libev.sh uninstall
其他事项:
客户端配置的参考链接:https://teddysun.com/339.html
安装完成后即已后台启动 Shadowsocks-libev ,运行:
/etc/init.d/shadowsocks status
可以查看进程是否启动。
本脚本安装完成后,会将 Shadowsocks-libev 加入开机自启动。
使用命令:
启动:/etc/init.d/shadowsocks start
停止:/etc/init.d/shadowsocks stop
重启:/etc/init.d/shadowsocks restart
查看状态:/etc/init.d/shadowsocks status
更多版本 Shadowsocks 安装:
ShadowsocksR 版一键安装脚本(CentOS,Debian,Ubuntu)
Shadowsocks Python 版一键安装脚本(CentOS,Debian,Ubuntu)
Debian 下 Shadowsocks-libev 一键安装脚本
Shadowsocks-go 一键安装脚本(CentOS,Debian,Ubuntu)
更新日志
2017 年 02 月 24 日:
1、恢复: 通过 Github API 自动获取 Shadowsocks-libev 的最新 release 版本的功能(v3.0.3)。
2017 年 02 月 13 日:
1、更新:升级版本到 3.0.2。
2017 年 02 月 12 日:
1、更新:升级版本到 3.0.1(请下载最新的脚本来安装)。
2016 年 11 月 05 日:
1、新增:判断是否已安装,若已安装,则获取版本号与最新版比较,然后可以升级覆盖安装;
2、修正:未安装时获取最新版本号的问题。
2016 年 09 月 23 日:
1、修正:偶尔自动获取版本号失败的问题;
2、新增:自动判断如果 VPS 存在 IPv6 地址,则在配置文件里添加监听 IPv6 地址。
2016 年 09 月 17 日:
1、重构代码,自动获取 Github 上最新版来安装,不再手动修改版本号;
2、自动检测本机是否已经安装,若已安装则正常退出(若要安装新版,则需先卸载);
3、改为下载 tar.gz 包来安装,不用依赖 unzip 命令。
2016 年 09 月 12 日:
1、更新:升级版本到 2.5.2。
2016 年 09 月 11 日:
1、更新:升级版本到 2.5.1。
2016 年 08 月 29 日:
1、更新:升级版本到 2.5.0;
2、修正:由于安装时文件名的更新,卸载时文件名改为一致。
2016 年 07 月 14 日:
1、更新:升级版本到 2.4.7。
2016 年 07 月 05 日:
1、修正:新增的依赖 xmlto、asciidoc;
2、修正:由于安装时文件名的更新,卸载时文件名改为一致。
2016 年 05 月 12 日:
1、新增:在 CentOS 7 下的防火墙规则设置。
2015 年 08 月 01 日:
1、新增:自定义服务器端口功能(如不设定,默认为 8989)。
2015 年 04 月 30 日:
1、修正:配置文件 /etc/shadowsocks-libev/config.json 同时启用 IPv4 与 IPv6 支持:
{
"server":["[::0]","0.0.0.0"],
"server_port":your_server_port,
"local_address":"127.0.0.1",
"local_port":1080,
"password":"your_password",
"timeout":600,
"method":"aes-256-cfb"
}
2、Shadowsocks libev 版不能通过修改配置文件来多端口(只能开启多进程),如果你需要多端口请安装 Python 或 Go 版;
特别说明:
1、已安装旧版本的 shadowsocks 需要升级的话,需下载本脚本的最新版,运行卸载命令
./shadowsocks-libev.sh uninstall
然后,下载最新版脚本即可安装最新版。
H5性能优化方案
H5性能优化方案
H5性能优化意义
对于一个H5的产品,功能无疑很重要,但是性能同样是用户体验中不可或缺的一环。原本H5的渲染性能就不及native的app,如果不把性能优化做起来,将极大地影响用户使用产品的积极性。
用户感受
当用户能够在1-2秒内打开H5页面,看到信息的展示,或者能够开始进行下一步的操作,用户会感觉速度还好,可以接受;而页面如果在2-5秒后才进入可用的状态,用户的耐心会逐渐丧失;而如果一个界面超过5秒甚至更久才能显示出来,这对用户来说基本是无法忍受的,也许有一部分用户会退出重新进入,但更多的用户会直接放弃使用。
一秒钟法则
移动互联网的架构、通讯机制,与有线网络有着巨大的差异,这也给H5的开发带来了很大的挑战。
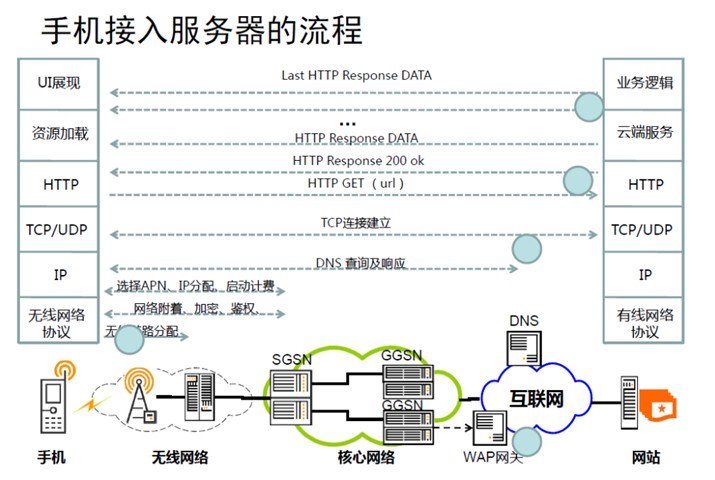
这是一张手机端接入服务器的流程。
首先,手机要通过无线网络协议,从基站获得无线链路分配,才能跟网络进行通讯。 无线网络基站、基站控制器这方面,会给手机进行信号的分配,已完成手机连接和交互。 获得无线链路后,会进行网络附着、加密、鉴权,核心网络会检查你是不是可以连接在这个网络上,是否开通套餐,是不是漫游等。核心网络有SGSN和GGSN,在这一步完成无线网络协议和有线以太网的协议转换。 再下一步,核心网络会给你进行APN选择、IP分配、启动计费。 再往下面,才是传统网络的步骤:DNS查询、响应,建立TCP链接,HTTP GET,RTTP RESPONSE 200 OK,HTTP RESPONSE DATA,LAST HTTP RESPONSE DATA,开始UI展现。
可见,通过运营商的网络上网,情况比较复杂,经过的节点太多;运营商的网络信号强度变化频繁,连接状态切换快;网络延迟高、丢包率高;网络建立连接的代价高,传输速度快慢不等(从2G到4G,相差很大)。
而我们优化的目标,就是所谓的一秒钟法则,即达成以下的标准:
- 2g网络:1秒内完成dns查询、和后台服务器建立连接
- 3g网络:1秒内完成首字显示(首字时间)
- wifi网络:1秒内完成首屏显示(首屏时间)
优化方案
资源加载
首屏加载
用户从点击按钮开始载入网页,在他的感知中,什么时候是“加载完成”?是首屏加载,即在可见的屏幕范围内,内容展现完全,loading进度条消失。因此在H5性能优化中,一个很重要的目的就是尽可能提升这个“首屏加载”的时间,让它满足“一秒钟法则”。
按需加载
首先要明确,按需加载虽然能提升首屏加载的速度,但是可能带来更多的界面重绘,影响渲染性能,因此要评估具体的业务场景再做决定。
Lazyload
Lazyload,即延迟加载,这并不是一个新的技术,在PC时代也是非常常用的一种性能优化手段。这个方案的原则是让屏幕外,或者不影响整体效果显示的图片、背景等资源,在界面就绪之后再进行网络加载。
滚屏加载
滚屏加载是一种常见的无刷新动态加载数据的方案,通常用在列表形式数据展示中。一方面,数据不是通过翻页进行加载,这样就避免了再一次请求和渲染整个页面;另一方面,数据显示的数量是受限的,例如第一次只请求了10条数据,也就只需要渲染这10条数据,下拉滚屏的时候,再去获得下面10条数据。
Media Query(响应式加载)
响应式设计是现在网站设计的一个流行趋势,随着移动互联网的发展,这项技术也越来越受到重视。通过这项技术,我们能够方便地控制资源的加载与显示,例如说在分辨率不同的手机上,分别使用不同的css,加载不同大小的图片资源。 方案参考: http://www.poluoluo.com/jzxy/201206/167034.html
第三方资源异步加载
第三方资源有的时候不可控,比如说页面统计、地图显示、分享组件等,这些第三方资源使用的时候要慎重选择,充分考察它们对于性能的影响,使用异步加载的方式进行,防止第三方资源的使用影响到页面本身的功能。
Loading进度条
在加载时间较长的时候,务必要让用户明确感知到加载完成的提示,通常是在加载过程中显示Loading的进度条,加载完成的时候隐藏它。从心理上,这会让用户有一种“期盼感”,而不至于太过枯燥。
对于一些重量级的H5应用,例如游戏,开始前需要加载很多资源才能让后面的游戏过程更为流畅,一个带百分比进度显示的进度条就更加重要。
避免30*/40*/50*的http status
-
200是一个正常的response,我们在浏览器中打开一个网页(后面会讲如何针对移动端进行调试),还会看到304,即命中浏览器缓存。这两种状态是正常的http status。
-
302、301跳转是常见的跳转,尤其前一种,在我们进行鉴权的时候有时会用到,但这个做法要尽可能地优化,一个页面访问,最多只进行一次302跳转即可,切忌频繁地跳转。
-
404、500,我们对自己开发的代码比较注意,一般不会发生,但是有的时候,加载第三方库,尤其是第三方库中有自己load组件的操作,这时,404和500错误可能会在你不知不觉的时候发生。例如钉钉的第三方微应用中,就遇到过dojo的组件加载问题,加载的一些子组件失败了,但是又没有影响页面显示,这就很容易被忽略。后面也会再讲,如何去测试和发现这样的隐患。
Favicon.ico
如果我们没有设置图标ico,则会加载默认的图标:域名目录下的favicon.ico。很多开发者没有注意到这一点,就会导致这个请求404或者500。
通常,我们在应用内部打开网页,不会显示这个图标出来(除非放到浏览器中显示网页),我们需要保证这个图标存在,尽可能地小(一般4KB以下),并且设置一个较长的缓存过期时间。
图片的使用
格式选择
显示效果较好的图片格式中,有webp、jpg和png24/32这几种常见的图片格式。一般来说,webp的图片最小,但在iOS或者android4.0以下的系统中可能会有兼容性问题需要解决。
-
Jpg是我们最常使用的方案,大小适中,解码速度快,兼容性问题也基本不存在,是我们在H5的应用中使用起来性价比最高的方案。
-
Png24或png32,一般来说,显示效果肯定会比jpg更好,但是实际上人眼很难感知出来,所以在H5应用中要避免这种格式的大图片。
对于少量的图片,推荐用智图或者tinypng等工具来帮助自己选择合适的大小、格式。
像素控制
在H5应用中,图片的像素要严格控制,一般来说不建议宽度超过640px。
小图片合并
在html网页中,如果有多个小图片需要加载,不妨试试CSS Sprites方案,尤其是一些基本不变,大小差不多的操作类型图标。
避免html代码中的大小重设
在html或者css中,如果有类似width: **px这样的代码,就要注意看一看了,如果说图片显示的效果是宽度100px,而下载的图片却是200px宽度,那这大小基本上就是所需要的4倍面积了,所以在H5应用中,使用图片的一个原则就是需要显示成多大,就下载多大的资源。
避免DataURL
DataURL是用Base64的方式,将图片变成一串文本编码放入代码的方式。这种方式有好处,因为它可以减少一次http交互的请求,对于一些体积特别小的图片,或者是动态生成的图片可以考虑使用。但在H5应用中,一般情况下,我们都是需要避免DataURL的,因为它的数据体积通常比二进制图片的格式大1/3,而且它不会被浏览器缓存,每次页面刷新都需要重新加载这部分数据。
使用图片的替代(css3, svg, iconfont)
CSS3和svg可以更好地使用GPU进行渲染加速,而且会避免增加图片资源导致的http请求增加。例如一些div的圆角效果,就完全可以用用css来实现。
Iconfont,可以认为是一种矢量类型的操作字体。如果页面中有较多的操作图标,可以考虑使用iconfont来替代图片资源。
域名/服务端部署
Gzip
服务端要开启Gzip压缩。
资源缓存,长cache
合理设置资源的过期时间,尤其对一些静态的不需要改变的资源,将其缓存过期时间设置得长一些。
分域名部署(静态资源域名)
将动态资源和静态资源放置在不同的域名下,例如图片,放在自己特定的域名下。这样的好处是,静态资源请求时,不会带上动态域名中所设置的cookie头信息,从而减少http请求的大小。
减少Cookie
尽量减少Cookie头信息的大小,因为这部分数据使用的是上行流量,上行带宽更小,所以传输速度更慢,因此要尽量精简其大小。
CDN加速
部署CDN服务器,或者使用第三方的CDN加速服务,优化不同地域接入网站的带宽速度。
代码资源
Javascript, CSS合并
尽量将所有的js和css合并,减少资源请求的次数。
外联使用js, css
外联使用js和css,这样可以有效地利用缓存,避免html页面刷新后重新加载这部分代码。
压缩html, js, css
压缩代码,尤其是js和css资源,压缩后的大小可以降低至原来的1/3以下,有效节约流量。
资源的版本更新
库js、css通常不会更新,但是我们的业务js和css可能会有更新,如果命中浏览器缓存,可能会让一些新的特性不能及时展现,甚至可能导致逻辑上的冲突。
因此对于这些js、css的资源引入,最好用版本号或者更新时间来作为后缀,这样的话,后缀不变,命中缓存;后缀改变,浏览器自动更新最新的代码。
Css位置
CSS要放到html代码的开头的head标签结束前。如果网页是动态生成的,那么在head代码完成后可以强制输出(例如php的flush()操作),这样的话,浏览器就会更快地解析出来head中的内容,开始下载css文件资源。
Js位置
Js放到前,这样的话,js的加载不会影响初始页面的渲染。
代码规范
避免空src
图片设置为空的src地址,在某些浏览器中可能会导致增加一个无效的http请求,因此要避免。
避免css表达式
可能会让页面多次执行计算,造成卡顿等性能问题。
避免空css规则
降低css渲染计算的成本
避免直接设置元素style
直接设置style属性,一方面在html代码中不利于缓存,另一方面也不利于样式的复用,因此要避免,通过指定id或者class的方式,在css代码块中进行样式调整。
服务端接口
接口合并
如果页面需要请求两部分以上的数据接口,建议将其合并,否则会增加一次http请求。
减少接口数据量
有的时候,服务端会把一些无关紧要的数据返回回来,尤其是类似于更新时间、状态等信息,如果在客户端不影响内容的逻辑展示,不妨在接口返回的数据中直接去掉这些内容。
缓存
缓存接口数据,在一些数据新旧敏感性不高的场景下很有作用,在非首次加载数据时候优先使用上次请求来的缓存数据,可以让页面更加快速地渲染出来,而不用等待一个新的http请求结束之后再渲染。这一点我们在后面还会再次提及。
其他一些建议
-
合理使用css
- 正确使用Display属性 Display属性会影响页面的渲染,因此请合理使用
- display:inline后不应该再使用width、height、margin、padding以及float
- display:inline-block后不应该再使用float
- display:block后不应该再使用vertical-align
- display:table-*后不应该再使用margin或者float
- 不滥用float
- 不声明过多的font-size
- 值为0时不需要单位
- 标准化各种浏览器前缀
- 无前缀应放在最后
- CSS动画只用 (-webkit- 无前缀)两种即可
- 其它前缀为 -webkit- -moz- -ms- 无前缀 四种,(-o-Opera浏览器改用blink内核,所以淘汰)
-
选择器
- 避免让选择符看起来像是正则表达式。高级选择器不容易读懂,执行耗时也长
- 尽量使用ID选择器
- 尽量使用css3动画
-
资源加载
- 使用srcset
- 首次加载不超过1024KB(或者可以说是越小越好)
-
html和js
- 减少重绘和回流
- 缓存dom选择和计算
- 缓存列表.length
- 尽量使用事件代理,避免批量绑定事件
- 使用touchstart,touchend代替click
- Html使用viewport
- 减少dom节点
- 合理使用requestAnimationFrame动画代替setTimeOut
- 适当使用Canvas动画
- TouchMove, Scroll事件会导致多次渲染
更快一步
前面的很多建议与普通的PC端web网页的开发是一致的,但是在移动互联网应用下,仅仅做到这些,可能只有60分,那么怎样才能得到80分甚至更高?
单页应用
钉钉的审批微应用,使用的就是单页架构。在这种架构下,基本不存在页面跳转的等待时间,只需要执行js逻辑触发界面变化,最多进行一次网络请求,获得服务端数据,其他资源均不需要再次请求。
资源离线
再快的网络交互,毕竟也是跨越了数个网络节点,因此一张图片、一个js,优化到了极致,也照样可能需要几百毫秒的时间来获得。因此想要打破这个极限,就要使用资源离线的策略。
在钉钉的微应用中,就使用了这样的一个“离线包”策略。一些固定的图片、js库等,被打包放入app中(或根据需要,在app启动的时候进行下载更新)。
微应用中,网页代码里面加载网络资源的需求,就变成了直接加载本地文件,速度自然得到再一次巨大的提升。
本地数据持久化和更新机制(版本管理)
对于一些时效性没有那么高的数据,可以考虑将接口数据缓存。那么页面的渲染将变成这样的流程:
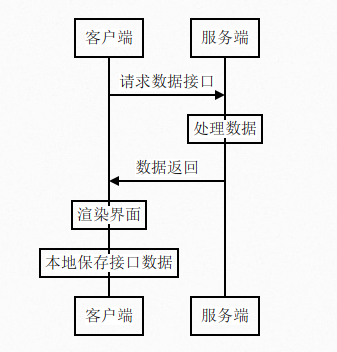
而非首次进入界面,流程如下:
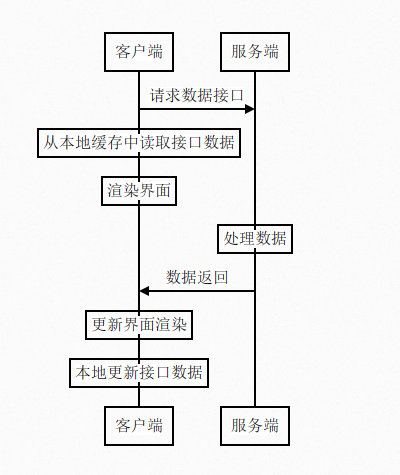
可以看出,在非首次进入界面的时候,页面不需要等待网络数据返回,就可以进行界面渲染,渲染的初始数据来自于本地的缓存,页面可以“秒开”。而当服务端的数据返回之后,本地的渲染会再次更新,缓存也被更新。
采用这样的方案有利有弊,好处显而易见,首屏加载的速度简直太快了——静态资源来自本地,数据接口来自本地,这在2G、3G或者其他网络速度较慢的时候,也可以让用户在极短的时间内就看到内容。但是这种方案也并非万能。
- 首次加载不可避免,还是会请求网络。
- 服务端有更新的时候,客户端不能够快速感知,页面可能还停留在一个“旧的版本”上,尤其是网络速度较慢时,可能还是需要经过好几秒,页面才会更新至最新版本。因此如果应用对数据的新旧很敏感的话,这种方案就不适合
- 数据更新后,需要重新渲染界面,界面刷新的性能消耗比正常情况更多,而且增加了程序的复杂度,容易出错。
预加载
有时,我们能够通过用户的行为统计,预判出用户下一步可能进行的操作。假设,我们统计出来针对某个微应用,用户首页渲染完成之后,大部分会点击列表中的第一个项目查看详情。那么在首页渲染完成之后,我们就可以先预先加载第一个项目的部分内容,那么针对这部分用户,他们实际点击之后,立即就能看到新的页面中的内容。
当然,这个方式也并不是在所有场景下都使用。一方面,需要做好充分的用户调研,掌握用户的使用习惯;另一方面,对于小部分用户而言,预加载所带来的就是不必要的流量消耗。
测试方案
工具准备
Chrome
在功能测试中,我们通常可以用chrome来测试不同的分辨率下,或是不同的设备上,网页的展现情况。在我们做性能优化的时候,也可以用这种方式来进行调试,方便地观察在特定设备上,静态资源是否按照我们想象的那样去加载了。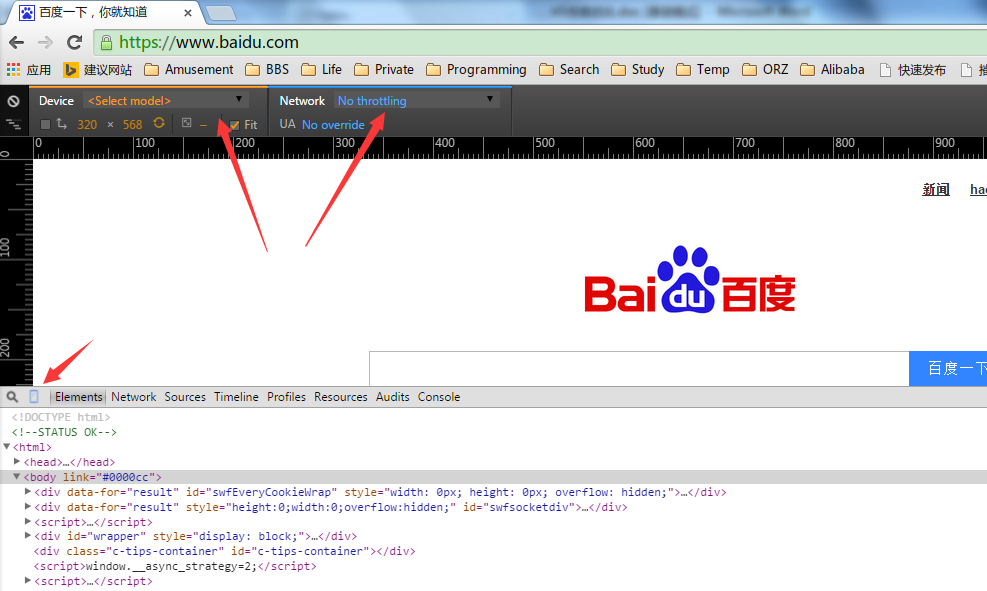
例如,我们想看下百度首页在某个设备下的表现。 通过F12进入控制台,点击图中的短箭头标示出来的那个设备图标,然后就可以在Device和Network中选择不同的设备和网络状况。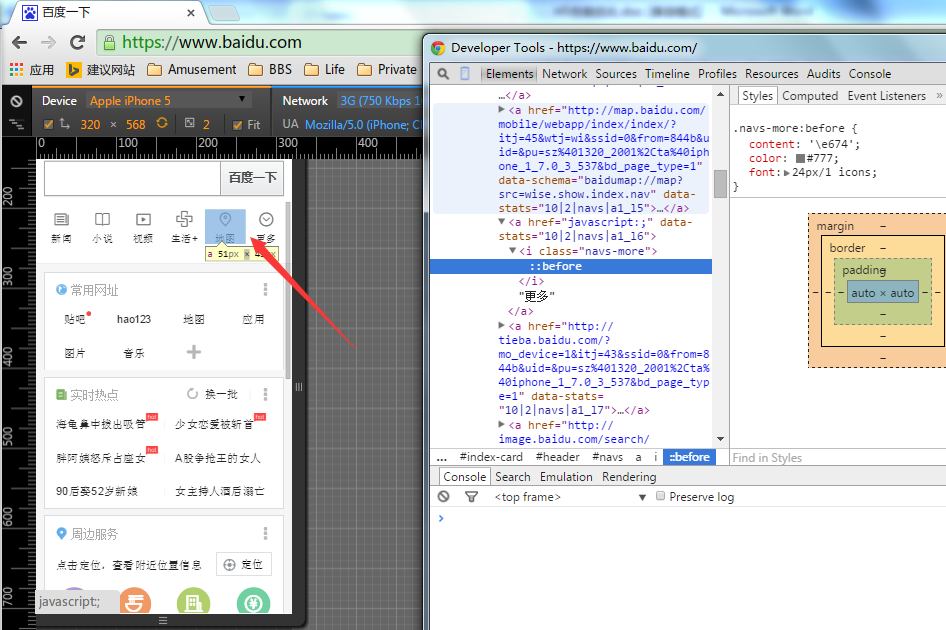
例如iphone5下,这个地图的图标,明显就可以看到是用iconfont来实现的效果。
当然,这个功能也仅仅是一种模拟,通过控制屏幕分辨率、UserAgent等来模拟设备请求,在实际的设备上,又该怎么查看呢?
还是Chrome,我们在地址栏中输入chrome://inspect (注意:Android版本需要是4.4+,并且应用中的WebView必须进行相应的调试声明配置)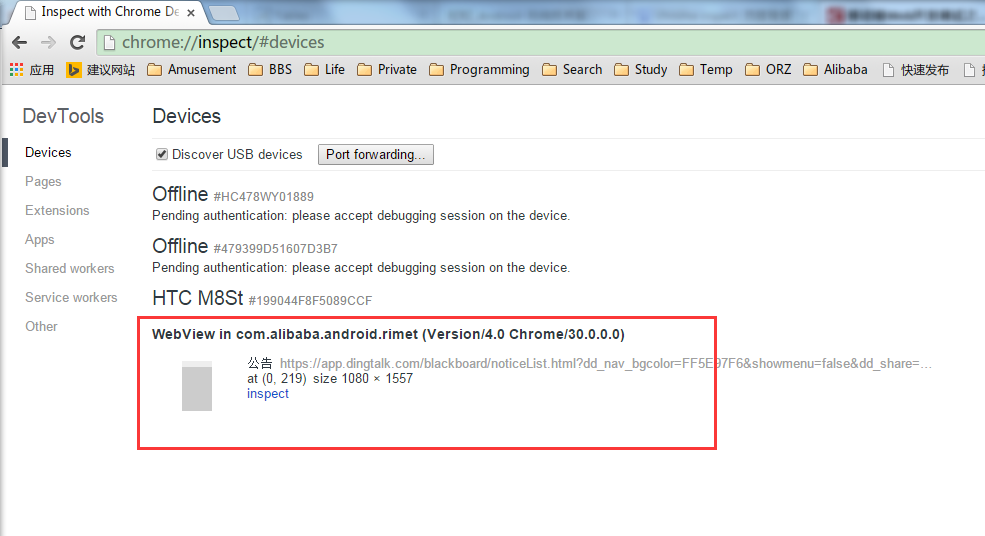
在这里点击inspect,则可进入我们熟悉的F12控制台界面,只不过debug的对象变成了我们在手机应用中的网页。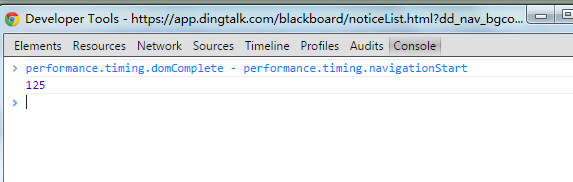
输入performance.timing.domComplete – performance.timing.navigationStart,就可以打印出网页加载的时间,domComplete表示所有的处理都已完成并且所有的附属资源都已经下载完毕。navigationStart表示开始加载新页面。两者相减,就代表这个网页完成渲染所需要的时间了。
同样地,我们可以在Elements tab中,debug网页,查看各个资源的使用,在Network中,看看加载了哪些资源,是否都做过了压缩。
然而,这种方式,还是有一定缺陷。 1. 如果打开网页经过了跳转,那么我们只能在这里看到最后一个url页面的加载情况。 2. 第一次打开页面的时候,在Network中,默认是不显示请求的详情的,当我们选择了preserve log upon navigation之后才会捕获,因此首次进入页面的加载情况,我们就很难获得了。
那么有没有一种方法,让我们能够更方便地去查看首次访问时,各种资源的加载使用情况呢?
Charles
Charles Proxy,可以说是H5测试的一个神器。 它的作用是在PC端开启一个代理服务器,手机连到这个代理服务器上之后,所有的http请求就都可以在这里看得清清楚楚。经过配置证书选项,https的请求也可以正常查看。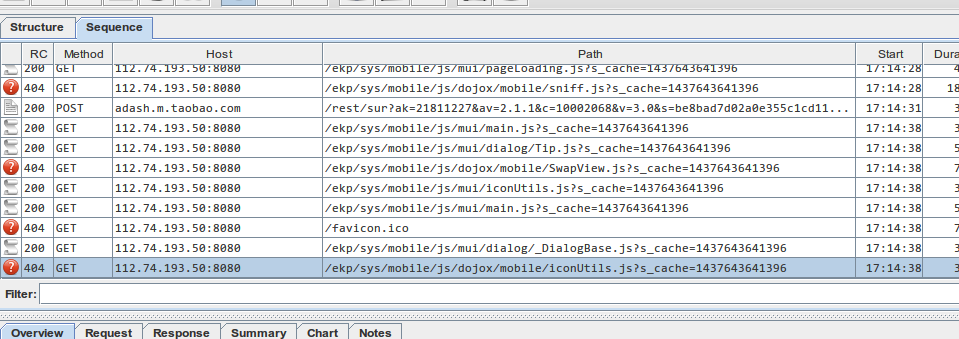
从图中,我们明显可以看到,有一些404的异常请求,这些都将对我们H5应用的性能造成影响。 如果我们发现有一些资源的Duration比较大,那这些可能是服务端响应太慢,自然也可以作为我们优化的依据。
测试标准
在钉钉的测试中,形成了一套标准。
|指标项|遵循的原则|优先级|检查项|说明| |:-|:-|:—|:—|:–| |内存|内存无泄漏|P0|主功能页面反复打开,功能的重复调用,内存无泄漏| 可以使用sysdump,也可以用我们开发的perfeasy工具进行观察| | | |P1|主功能页面,持续操作,退出后,内存占用不超过总内存的5%|perfeasy| |CPU|减少无端的CPU使用|P1|灭屏,静置2分钟,在5分钟内CPU使用平均1%|adb连接后, 使用top命令| ||||主干功能正常操作CPU占用不超过60%, 持续5秒|perfeasy| |电量|避免无端电量消耗|P0|灭屏状态下,无线程持续运行|一般来说, 静置cpu正常, 这一项就没有问题| ||||灭屏,window.setTimeout()方法停止|一般来说, 静置cpu正常, 这一项就没有问题同上| ||||灭屏,window.setInterval()方法停止|同上| ||||ajax超时时间设置为5000ms以内|结合代码| ||||ajax无retry逻辑|结合代码| |资源|资源的正确使用|P0|是否存在资源的重复拉取|charles| |||P1|H5页面首屏总大小不超过200K|charles, chrome| |||P1|抓包检查(js/css/html)代码去除了空格/注释,JS文件变量名变成a/b等代替|charles, chrome| |||P1|H5引用的单张图片小于60K|charles, chrome
如果影响了显示质量, 可酌情调整| |流畅度|确保给到用户流畅的展示体验|P1|流畅的实时动画展示,avgFPS>=45|perfeasy| |时延|确保给到用户流畅的切换体验|P0|wifi网络下,首次进入页面onload时间<1000ms|Chrome| |时延|确保给到用户流畅的切换体验|P0|wifi网络下,首次进入页面onload时间<1000ms|Chrome| ||||wifi网络下,非首次进入页面onload时间<500ms|Chrome| ||||3G正常网络, 首次进入页面onload时间<2000ms|chrome, 树莓派模拟3G| ||||3G正常网络, 非首次进入页面onload时间<1000ms|chrome, 树莓派模拟3G|
经典案例
图片未优化
通过charles可以方便地进行测试。 从请求监控的情况看,有一张图片超过了60KB,宽度640px,但是在应用中,实际显示的是一张小缩略图,是通过代码控制让它显示成小图的,因此修改方案很简单,将所有头像的图片均改为获取120px宽度的即可。
按需加载
-
钉钉的教学页面
- 多个slide页面, 每个页面有2-3个图片, 其中有一个是大图显示
- 图片是客户提供的, 最大的图片大约是300KB以上
- 第一次进入页面后, 所有slide的图片均进行加载
- 3G网络下, loading的图标大约持续6000ms后才会消失
-
优化方案
- 尽可能优化图片, 但是压缩后发现噪点明显增加, 影响了显示效果
- 修改加载方案, 第一次进入后, 只加载本页的图片
- loading时间降低至1秒左右
最后插播一条广告:)
钉钉开放平台招聘微应用容器iOS工程师 负责钉钉客户端微应用iOS容器开发,参与钉钉iOS容器研发/发布/监控平台建设,建造航母级H5应用基础设施,保障线上产品质量;
需要你:
- 精通iOS开发,熟练掌握Objective-C语言,C/C++ 语言;熟悉Cocoa开发框架,了解业界技术发展状况;
- 熟悉iOS开发工具和相关开发测试工具的使用
- 熟悉HTML5、CSS3和JavaScript,掌握HTTP及相关网络协议,熟悉跨终端、跨浏览器的开发模式和平台特性;
巧用域名发散,缓解域名发散限制
说到优化,其实机会不多,费力不讨好,但需求不少,而且往往是刚需。一般来说针对请求优化的思路都是“收敛”,但是在这篇文章中,我们剑走偏锋,反其道行之,利用域名发散的方式缓解并发请求的限制。
最近后端前辈的带领下做一件“大事儿”,将原有的基于页面的广告请求改为行业内比较先进的单广告位请求。随之带来了好多未知的坑。过去一个页面只发出一个异步请求,现在要发出1*广告位数的请求,这一个页面50-110的请求数无论对于后台能否承接高并发还是前端对大量异步回调的处理,都是挑战。但是单广告位有事只能投放的先提条件,身为广告人,怎能不迈出这一步呢。
这次我们就先看看其中一个坑。我的一个页面中有100 多个广告位,要在页面刚加载的时候,并发100个异步请求。首先服务端的压力就不小,前端同时并发这么多的请求也会有一系列的问题:
1、大量的异步请求所带来的大量的回调,注意这些回调并不是按请求的顺序返回的;
2、浏览器并发限制,浏览器针对同一个域名可并发的请求数量是有限的,平均下来是6个。很明显我这100多个广告位请求要分好多批出发啊?

为什么要这么多的请求?
一开始的时候我也在问这个问题,毕竟在做单广告位之前,我好不容易写了一个基于页面的广告展示代码(一个页面只有一个请求,包含这个页面所有需要展示的广告数据)。那时候风和日丽、岁月静好、大错不出、小错不少。后台仅仅提供有数据的广告位,我将他们按照业务逻辑展示。但是后端前辈的鸡汤太好喝加之确实这段时间一直有一些问题解决不了,就是我们的广告后台只是将广告定位到了页面,而没有定位到具体的广告位;广告后台需要针对具体的广告位进行智能投放;后台需要对页面上的所有广告数据进行一次打包,就不得不在广告后台加入页面的概念,这完全是为了应对现有的模式,理想中广告投放后台应该专注于用户画像和针对资源(广告位)的服务,而前端也不该直接对广告位进行处理。这样两端都去掉页面这一层才是更好的选择,同时这也是业内普遍公认的处理办法——“单广告位请求”(智能广告的基石)。
出问题了——异步回调,啥时候干活
我们的广告逻辑要求一部分广告马上显示,这部分还好,回调就渲染;另一部分要求分好几批次展示,这我就要等这部分“贵族广告”都回来了在启动渲染。但是单广告位请求就不得不面临一个问题——丢包。如果发100个,回来99个,那我的99个还不展示了?这问题不难,相信你心中肯定有答案了,不就是设定一个“截至时间”吗,但是和下面问题混在一起就要多考虑一点了。
又出问题了——并发请求
既然没有选择原地踏步,而是勇敢前行,就要踩坑。第一个问题就是太慢,100多个好几批要很长时间才回来,我后续的广告渲染要等多久?时间长了,能保证都回来,但用户体验太差;时间太短,体验好了,但是100多个请求来不及回来。看来这个“截止时间”不好定。
最终业务方选择了用户体验,毕竟广告本就是异步渲染,在等要等多久啊!这样我就只有一条路了——“提速”,优化请求的耗时,能在截至时间内那会所有的请求。那么我们来看一下耗时由那些部分组成:
|
1
|
单一请求耗时=发出请求耗时+网络延时+服务器计算响应时间+网络延时
|
从上面来,网络不是我们能控制的、服务端也已经加上了两级缓存,看好像没有前端能优化的部分哈,但是这里仅仅是一个请求的耗时,100个旧不是这样了。100个请求并不是一口气都发出去,而是被浏览器限制住了。浏览器为了方式同一个域名下的并发请求过多,从而做了安全限制,一般允许同一域名同时发出6个请求,如果每一个请求的耗时固定,并且网络带宽正常,总的耗时应该取决于最后一个请求发出的时间:
50个

100个

|
1
|
总耗时=最后一个请求的等待时间+单一请求耗时
|
通过demo我们可以看出50个请求总耗时391ms减去dom ready ,50个请求耗时 = 391 - 155 = 236ms;100个请求耗时 = 850 - 214 = 636ms
单一请求,我优化不了,但我可以减少最后一个请求的等待时间。那么等待时间是由什么决定的呢?等待时间是由同域并发请求限制造成的。虽然域名收敛时后续请求可以利用长链接来减少开销,感觉会“快一点”,但是浏览器限制了并发请求数。如果我们走另一条路(域名发散)呢?经过我的测试发散后单广告位的并发请求数又明显提高,50个广告位2个域名,总耗时=259 – 157 = 102ms 节约了134ms 减少56.7%。100个域名3个域名总耗时 = 428 - 256 = 172ms 节约了464ms 减少72.9%。当然这是理想环境下,优化率较高。观察上线效果,总耗时减少在30%-50%这个范围内。
50个

100个

怎么(利用域名发散)做的?
其实很简单,我们对同一个服务申请多个域名。换个名字,浏览器就分别限制了,两个域名不就并发12个了嘛!这样并发的多了,等待的就少了,自然最后一个请求的等待时间,就大幅减少。总耗时也就可控在用户体验上可接受的范围。
开发和测试的时候我们通过绑hosts的方式让服务器IP 有好几个“外号”,当然上线的时候还是要麻烦运维同事部署到公网环境。
是不是域名越发散(越多)越好?
当然不是的,我们刚才提到域名收敛有一个最大的好处就是:后续的请求可以利用第一次建立好的长链接来减小网络开销,从而“提速”。当我100个请求,10个域名,就要建立10次链接。开销也不小。我们在域名收敛和域名发散之间需要折中一下。当然我在实际开发中发现50个请求时4个域名就已经比3个的耗时长了,而且3个域名的总耗时不是很稳定。我最终决定根据广告位数量来判断使用几个域名。30个请求以下使用1个域名;70个请求以下使用2个域名;120以下使用3个域名。
总结:
实际工作中网站优化的机会不多,优化过静态请求的同学一定都知道合并静态资源。其背后正是“域名收敛”的思想。但是一般网站合并静态资源后,刨除内容图片资源懒加载的数量,往往js、css、精灵图的总量往往不会太多而且通过按需加载,往往不会产生如此大的并发请求。像单广告位请求这高并发的应用场景还是不多见,我们利用域名收敛、发散这样的一些基础理论却解决复杂棘手的问题。想来无论外界对前端价值褒贬不一,做前端开发还是挺有意思的。
把php5.3升级成5.6 并开启opcache
原来的php都打包成rpm 后 直接安装的,可以免去安装扩展
今天想把机器上面的php5.4 升级到5.6去 为了防止漏掉参数就直接在info上面复制的 Configure Command 编译参数
本来以为不用安装扩展了 发现还是需要把扩展安装好后才能安装
因为rpm源里面没有libmcrypt-devel 所以使用源码安装
扩展安装好后就可以编译过了
php-fpm.conf 就从原来的地方复制过来,把启动脚本改下就可以了
这样可以启动php5.6了 然后给它加上opcache 加速
因为我们在编译的时候没有加上–enable-opcache 所以要到
cd php-5.6.29/ext/opcache /usr/local/php/bin/phpize ./configure --with-php-config=/usr/local/php/bin/php-config make
make install |
然后到php.ini里面加上扩展和配置
Zend OPcache 一栏
关于微信小程序一些问题的思考认识
“关于微信小程序一些问题的思考认识”
————清秋·2017.1.9
2017年1月9日,微信小程序开闸放水。
无论白昼夜晚,因小程序不眠席卷。一个时代在开启,未来怎么样,谁也无法准确预测。
关于小程序,喧嚣背后,很多问题是需认识思考的。
1.入口
2.体验
3.推广传播
4.与App的博弈刚刚开始
5.小程序的野心——线下虚拟未来
6.商业化
【入口问题】
小程序的入口有五种。
1.二维码获取(强调的是线下扫码,封锁了一切的线上引流渠道)
2.微信搜索(微信客户端首页直接精准搜)
3.公众号关联(1个公众号能绑定5个小程序,1个小程序只能绑定1个公众号)
4.好友推荐(发现一个小程序,可以通过转发某个小程序的某页面给好友,或者转发到群,不能在朋友圈分享传播)
5.历史记录查找
就入口问题而言,微信并不存在一个进行小程序分发的入口。也正是为什么很多朋友没有体验过,需要体验才会显示的缘由之一。
【体验问题】
尝试了很多小程序,第一次打开的速度是超级慢,但只要有了第一次速度会超级快,部分小程序反应直接秒杀原生App。
【推广传播问题】
市面上不乏已经有做小程序聚合分发的应用商店。很显然,被微信封杀之日,为期不远。并非任何此类聚合可以单独场景化。
关于传播推广,张小龙讲二维码是小程序最好的传播路径。但从实际来看,当下乃至很长一段时间内,第一波甚至是最好的传播路径,是“群”。
【与App的博弈刚刚开始】
小程序的出现从某种程度上对App的冲击很大,但塞翁失马焉知非福。
事实上小程序并没有想象的那么夸张。并不是小程序来了,所有App将死无葬身之地。从目前情况来看:
订阅号及高频次社交、媒体类APP不可取代;
纯工具、低频次App受到的冲击将会很大。
对部分产品而言,无疑小程序也成为了原生App一个很好的拉新方式。但对整个原生App而言,App与小程序的博弈战终究会愈演愈烈,这只是开始。
【小程序与线下虚拟未来】
张小龙讲小程序,没有入口、没有应用商店、不做订阅、不能推送、不能分享到朋友圈、不做游戏、不协助引流、和公众号相互独立。
作为不沉淀社交关系,也不订阅和粉丝关系的小程序,它似乎就是一个连接线下服务的线上入口。
放眼当下,直指线下与虚拟未来,这必将是它的野心。那么,商业化的问题随之而来,也就值得深思。
【商业化问题】
那么多企业在开发小程序,尽管他们受制于微信的封闭生态和审核机制。所谓无利不起早,微信团队本身乃至外界都在寻找小程序的价值与突破口。
这条路可能是漫长的,但这条路的主基路线不会改变。任何产品都有产品生命周期,小程序的发展也不例外。
小程序的弊端也正是商业化,这是它不容忽视的短板。倘若企业走的不是电商模式,小程序的商业化很困难。那么,企业开发它的价值最终归属到哪里?当深思。
从遍地都是小程序,到开发者为自个儿的小程序寻找商业化,再到好的小程序被留下,差的被淘汰。这个过程,场景互联不仅是微信的生态,也是“大用户”的生态。
小程序是奔场景互联而来,商业化问题也终究会被提上日程,最起码并不是为了好玩。所以说就商业化而言,小程序能走多远很难说,看看之前的Html5和服务号就不难想象。
但不可否认的是,对普通C端用户而言,用完即走,福音如是。无论如何,一个新时代开始了。
php获取文件mime类型Fileinfo等方法
php如何获取文件(图片)的mime 类型呢?可以使用php mime_content_type()函数,使用开发用的ubuntu server lamp的默认配置测试后完全支持,返回了正确的文件mime type。但是将该API项目移植到Centos 5.2(内核2.6) LAMP环境时,出现了如下错误提示:
Fatal error: Call to undefined function: mime_content_type()
最后查看了最新的php手册发现php mime_content_type()函数已经被废弃,当然官方不推荐使用,而且需要经过适当的php配置后才能使用。因此要获取图片或其他的文件的 MIME类型,Fatal error: Call to undefined function: mime_content_type()错误就有了以下几种解决方案。
mime_content_type()函数判断获取mime类型
如果对已被php 5.3.0废弃的mime_content_type()函数仍然情有独钟,那么可以对php进行配置启用magic_mime扩展。比如Centos下使用phpinfo()查看php apache配置,查找到mime-magic,如果显示“–without-mime-magic”,则要编译php切换到”with-mime-magic“选 项。mime_content_type()函数还依赖于Apache httpd 的magic文件(mime_magic.magicfile),为了检测文件的MIME类型,必须配置告知magic文件的地址,如’–with- mime-magic=/usr/share/file/magic.mime’。Windows环境下还需要在php.ini中添加:
mime_magic.magicfile = “$PHP_INSTALL_DIRmagic.mime”
其中$PHP_INSTALL_DIR是你的php安装目录。在有些LAMP环境下,这个mime_magic文件不一定存在或可读,还要另外下载。另外有些虚拟主机为了安全考虑,即使是有with-mime-magic也不一定会返回正确的mime类型,有时候会返回空字符串。因此,就凭mime_content_type()函数已经被废弃这一项,就不推荐使用该方法获取文件MIME类型了。
php Fileinfo 获取文件MIME类型(finfo_open)
PHP官方推荐mime_content_type()的替代函数是Fileinfo函数。PHP 5.3.0+已经默认支持Fileinfo函数(fileinfo support-enabled),不必进行任何配置即可使用finfo_open()判断获取文件MIME类型。Centos 默认安装的LAMP环境php版本还是PHP5.2.6,低于5.3.0版本则可能出现类似错误提示:PHP Fatal error: Call to undefined function finfo_open() in…。因为之前的php版本,需要加载magic_open类,fileinfo函数属于PECL扩展,启用fileinfo PECL扩展才能检测MIME类型。所以有两种途径使用fileinfo获取文件的MIME类型。
将php版本升级到5.3.0以上。php官方也已经不再维护和更新这个fileinfo pecl扩展包,所以升级是最好的办法。
安装fileinfo pecl扩展,Centos linux 如何安装fileinfo:在Centos下面安装fileinfo命令(rpm):yum install php-pecl-Fileinfo。或使用源码安装编译:
Fatal error: Call to undefined function: mime_content_type()
最后查看了最新的php手册发现php mime_content_type()函数已经被废弃,当然官方不推荐使用,而且需要经过适当的php配置后才能使用。因此要获取图片或其他的文件的 MIME类型,Fatal error: Call to undefined function: mime_content_type()错误就有了以下几种解决方案。
mime_content_type()函数判断获取mime类型
如果对已被php 5.3.0废弃的mime_content_type()函数仍然情有独钟,那么可以对php进行配置启用magic_mime扩展。比如Centos下使用phpinfo()查看php apache配置,查找到mime-magic,如果显示“–without-mime-magic”,则要编译php切换到”with-mime-magic“选 项。mime_content_type()函数还依赖于Apache httpd 的magic文件(mime_magic.magicfile),为了检测文件的MIME类型,必须配置告知magic文件的地址,如’–with- mime-magic=/usr/share/file/magic.mime’。Windows环境下还需要在php.ini中添加:
mime_magic.magicfile = “$PHP_INSTALL_DIRmagic.mime”
其中$PHP_INSTALL_DIR是你的php安装目录。在有些LAMP环境下,这个mime_magic文件不一定存在或可读,还要另外下载。另外有些虚拟主机为了安全考虑,即使是有with-mime-magic也不一定会返回正确的mime类型,有时候会返回空字符串。因此,就凭mime_content_type()函数已经被废弃这一项,就不推荐使用该方法获取文件MIME类型了。
php Fileinfo 获取文件MIME类型(finfo_open)
PHP官方推荐mime_content_type()的替代函数是Fileinfo函数。PHP 5.3.0+已经默认支持Fileinfo函数(fileinfo support-enabled),不必进行任何配置即可使用finfo_open()判断获取文件MIME类型。Centos 默认安装的LAMP环境php版本还是PHP5.2.6,低于5.3.0版本则可能出现类似错误提示:PHP Fatal error: Call to undefined function finfo_open() in…。因为之前的php版本,需要加载magic_open类,fileinfo函数属于PECL扩展,启用fileinfo PECL扩展才能检测MIME类型。所以有两种途径使用fileinfo获取文件的MIME类型。
将php版本升级到5.3.0以上。php官方也已经不再维护和更新这个fileinfo pecl扩展包,所以升级是最好的办法。
安装fileinfo pecl扩展,Centos linux 如何安装fileinfo:在Centos下面安装fileinfo命令(rpm):yum install php-pecl-Fileinfo。或使用源码安装编译:
cd /usr/src/down && wget http://pecl.php.net/get/Fileinfo-1.0.4.tgz
tar zxvf Fileinfo-1.0.4.tgz
cd /usr/src/down/Fileinfo-1.0.4 && phpize && ./configure && make && make install
还可以使用网上流传较多的一种方法,Linux通过phpize使用pecl指令来安装fileinfo:
若没有phpize指令,需要先安装。#phpize检测若提示”No command ‘phpize’ found”,则需先安装phpize;
下载安装php-devel(php5-dev)的rpm,安装phpize;
service httpd restart 或 reboot;
命令 pecl install fileinfo 安装fileinfo扩展。
安装完毕,/usr/lib/php/module目录下多了fileinfo.so文件,/usr/share/file目录下多了magic.mime和magic两个文档
修改php.ini配置:加入 extension=”fileinfo.so”
service httpd restart
Windows服务器下安装fileinfo相似,php.ini:extension=php_fileinfo.dll
image_type_to_mime_type()获取图片MIME类型
如果我们需要判断MIME类型的文件只有图像文件,那么首先可以使用exif_imagetype()函数获取图像类型常量,再用 image_type_to_mime_type()函数将图像类型常量转换成图片文件的MIME类型。同样php.ini中要配置打开 php_mbstring.dll(Windows需要)和extension=php_exif.dll。phpinfo()“–enable-exif”。首先exif_imagetype返回的是图像类型常量(Imagetype Constants),如IMAGETYPE_GIF、IMAGETYPE_JPEG、IMAGETYPE_PNG等。
<?php
$image = exif_imagetype(“f:\test.jpg”); //本地路径或远程图片地址均可 IMAGETYPE_GIF//
$image = exif_imagetype(“http://www.phpec.org/logo.gif”);
$mime = image_type_to_mime_type($image);
echo $mime; // 输出image/jpeg
?>
php上传文件获取MIME类型
如果使用php上传文件,检测上传文件的MIME类型,则可以使用全局变量$_FILES[‘uploadfile’][‘type’],由客户端的浏览器检测获取文件MIME类型。
Centos 系统或其他环境下若都不方便获取文件MIME类型的话,还有最后一种绝对可行的方法,就是读取文件名后缀,根据后缀名一一对应文件的MIME类型,具体可以参考php手册上的这条评论。当然这种方法检测到的MIME文件类型不一定是非常准确的。
如果又很不幸的出现 call an undefined function exif_imagetype()
打开扩展 extension=php_exif.dll
并将extension=php_mbstring.dll ,放到extension=php_exif.dll前边
使用tinyproxy stunnel搭建 https proxy 服务器
在各种上网的方法当中,https proxy 可能是最简单、方便、快速的,它免去了 vpn 各种拨号连接的麻烦,也免去了安装各种客户端的麻烦,同时搭建所用的软件也是历史悠久的非常稳定。
吐槽:如果问为什么这么好的方式却很少人用,答案可能是因为它需要较多的¥money,而且可能需要一张双币/多币种信用卡来购买这些东西:一个虚拟服务器 vps,一个域名,一个 SSL 证书。vps 我比较推荐 linode,并不是因为你戳一下这个链接并成功购买后能返回一点零钱给我,而是 linode 相当厚道,它会跟随主流免费为你升级 CPU、内存、硬盘、带宽等等。域名和 SSL 证书大家可以参考我的前一篇《如何购买廉价 SSL 证书》。全部扔上购物车一年大概 $150 以上,捉襟见肘的可以考虑多人合购。
好了说回正题,用于实现 https proxy 的服务端软件很多,可以用老掉牙但很稳定的 squid,也可以随便用一个轻量级的 http proxy 程序搭配老掉牙的 stunnel,或者试试新秀 node-spdyproxy 也可以。
下面介绍一下比较简单的方案:轻量级 http proxy 程序 tinyproxy + stunnel 。
1、安装 c和 stunnel
首先使用各个 Linux 发行版的包管理器安装 tinyproxy 和 stunnel,比如:
$ sudo yum install tinyproxy stunnel // 对于 centos linux
$ sudo pacman -S tinyproxy stunnel // 对于 arch linux
安装完成后顺便设置它们随开机启动(可选)。
2、设置 stunnel
把你证书私钥和购买的证书扔到 /etc/stunnel 里,然后编辑文件 stunnel.conf,先指定私钥和证书文件名:
cert = /etc/stunnel/mycert.pem
key = /etc/stunnel/mykey.pem
需要注意的是从证书服务商购买回来的证书通常是几个小文件,大概有是:一个你的域名证书,一个证书链证书,一个root证书。把它们用文本编辑器打开,然后按照上述的顺序复制粘贴成一个文件,这个文件就是上面 ”cert=“ 这行所需的文件。
然后指定端口转换,比如将端口 443 (https 的默认端口)绑定并转换到 tinyproxy 的默认端口 8888:
[https]
accept = 443
connect = 127.0.0.1:8888
其中 https 这个一项绑定的名称,可以随便起,accept 表示本机监听的端口,connect 表示转换到哪里。完整的意思就是为 127.0.0.1:8888 添加 SSL 加密层,然后通过 443 端口对外服务。
3、客户端设置
目前默认支持 https/spdy 代理的只有 google chrome 浏览器(其他浏览器需要在客户端运行 stunnel 把 https 翻译为 http 才能使用)。而且很诡异的是 chrome 没有自己独立设置 proxy 的地方,使用系统全局的那个 https 设置是不行的(因为系统那个 https 代理指的是当你访问 https 的网站时所走的 http 代理通道,跟我们这篇说的 https proxy 是两码事),所以你还得在 chrome 浏览器里安装插件 TunnelSwitch,然后在这个插件里设置 https 代理为:“你的网站域名:443”,这样所有工作都完成可以直接上网了。
4、一个给爱折腾的人的省钱方案
如果想节省购买 SSL 证书的花费,那么自己生成一个“自签名”的证书也是可以的,不过如果你的 proxy 想共享给其他人使用的话,要慎重考虑这种方式,因为它会让不爱折腾的人觉得很折腾。
用下面命令即可生成一个自签名证书:
openssl genrsa -out key.pem 1024
openssl req -new -key key.pem -subj "/CN=localhost" -out req.pem
openssl x509 -req -days 365 -in req.pem -signkey key.pem -out cert.pem
注意要将上面的 localhost 更改为你的域名,最终有用的分别是私钥文件 key.pem 和证书文件 cert.pem,把这两个文件替换上面第二步所提到的位置即可。
然后在客户端需要导入这个 cert.pem 才能顺利使用你所搭建的 https proxy 服务。各个操作系统的导入证书方法都不太相同。
- 在 linux 里比较麻烦,需要用 libnss3 工具 certutil 来完成,命令如下:
$ certutil -d "sql:$HOME/.pki/nssdb" -A -n dummy -i cert.pem -t C
- 在 mac osx 里使用 keychain 工具,把证书拖进”证书“一栏里。
- 在 windows 里双击证书文件,在选择“导入到位置”那一步选择”根信任“。
然后重启你的 chrome 浏览器就可以了。
Nginx Google 扩展,让google反向代理的配置和使用wen.lu一样简单.
en.lu 一路走到现在, 离不开大家的支持!
很多朋友通过各种方式问过我: “你丫怎么不开源啊…”
先向那些朋友道歉啊, 其实不是我不想开源, 只是之前的版本配置实在太复杂.nginx三方扩展用了一大堆, 外加lua, 以及突破千行的配置工程, 这么拙劣的技艺, 实在不好意思拿出来分享
遂决定写一个扩展, 让google反代的配置和使用wen.lu一样简单.
location / { google on;
}
你没有看错, “一行配置, google 我有!”
现在 g2.wen.lu 就是由该扩展驱动

依赖库
安装
以 ubuntu 14.04 为例 i386, x86_64 均适用
最简安装
# # 安装 gcc & git # apt-get install build-essential git gcc g++ make # # 下载最新版源码 # nginx 官网: # http://nginx.org/en/download.html # wget "http://nginx.org/download/nginx-1.7.8.tar.gz" # # 下载最新版 pcre # pcre 官网: # http://www.pcre.org/ # wget "ftp://ftp.csx.cam.ac.uk/pub/software/programming/pcre/pcre-8.38.tar.gz" # # 下载最新版 openssl # opessl 官网: # https://www.openssl.org/ # wget "https://www.openssl.org/source/openssl-1.0.1j.tar.gz" # # 下载最新版 zlib # zlib 官网: # http://www.zlib.net/ # wget "http://zlib.net/zlib-1.2.8.tar.gz" # # 下载本扩展 # git clone https://github.com/cuber/ngx_http_google_filter_module # # 下载 substitutions 扩展 # git clone https://github.com/yaoweibin/ngx_http_substitutions_filter_module # # 解压缩 # tar xzvf nginx-1.7.8.tar.gz
tar xzvf pcre-8.38.tar.gz
tar xzvf openssl-1.0.1j.tar.gz
tar xzvf zlib-1.2.8.tar.gz # # 进入 nginx 源码目录 # cd nginx-1.7.8 # # 设置编译选项 # ./configure \
--prefix=/opt/nginx-1.7.8 \
--with-pcre=../pcre-8.38 \
--with-openssl=../openssl-1.0.1j \
--with-zlib=../zlib-1.2.8 \
--with-http_ssl_module \
--add-module=../ngx_http_google_filter_module \
--add-module=../ngx_http_substitutions_filter_module # # 编译, 安装 # 如果扩展有报错, 请发 issue 到 # https://github.com/cuber/ngx_http_google_filter_module/issues # make
sudo make install # # 启动, 安装过程到此结束 # sudo /opt/nginx-1.7.8/sbin/nginx # # 配置修改后, 需要 reload nginx 来让配置生效, # sudo /opt/nginx-1.7.8/sbin/nginx -s reload
从发行版迁移
# # 安装 gcc & git # apt-get install build-essential git gcc g++ make # # 安装发行版 # (已安装的请忽略) # apt-get install nginx # # 查看发行版编译选项及版本 # nginx -V # nginx version: nginx/1.4.7 # built by gcc 4.8.2 (Ubuntu 4.8.2-19ubuntu1) # TLS SNI support enabled # configure arguments: # --with-cc-opt='-g -O2 -fstack-protector --param=ssp-buffer-size=4 -Wformat -Werror=format-security -D_FORTIFY_SOURCE=2' \ # --with-ld-opt='-Wl,-Bsymbolic-functions -Wl,-z,relro' \ # --prefix=/usr/share/nginx \ # --conf-path=/etc/nginx/nginx.conf \ # --http-log-path=/var/log/nginx/access.log \ # --error-log-path=/var/log/nginx/error.log \ # --lock-path=/var/lock/nginx.lock \ # --pid-path=/run/nginx.pid \ # --http-client-body-temp-path=/var/lib/nginx/body \ # --http-fastcgi-temp-path=/var/lib/nginx/fastcgi \ # --http-proxy-temp-path=/var/lib/nginx/proxy \ # --http-scgi-temp-path=/var/lib/nginx/scgi \ # --http-uwsgi-temp-path=/var/lib/nginx/uwsgi \ # --with-debug \ # --with-pcre-jit \ # --with-ipv6 \ # --with-http_ssl_module \ # --with-http_stub_status_module \ # --with-http_realip_module \ # --with-http_addition_module \ # --with-http_dav_module \ # --with-http_geoip_module \ # --with-http_gzip_static_module \ # --with-http_image_filter_module \ # --with-http_spdy_module \ # --with-http_sub_module \ # --with-http_xslt_module \ # --with-mail \ # --with-mail_ssl_module # # 下载对应 nginx 大版本 # nginx 官网: # http://nginx.org/en/download.html # wget "http://nginx.org/download/nginx-1.4.7.tar.gz" # # 下载本扩展 # git clone https://github.com/cuber/ngx_http_google_filter_module # # 下载 substitutions 扩展 # git clone https://github.com/yaoweibin/ngx_http_substitutions_filter_module # # 安装依赖库的 dev 包 # apt-get install libpcre3-dev libssl-dev zlib1g-dev libxslt1-dev libgd-dev libgeoip-dev # # 请对照自己发行版的 configure 参数进行 configure, 勿直接 copy 以下配置 # ./configure \
--with-cc-opt='-g -O2 -fstack-protector --param=ssp-buffer-size=4 -Wformat -Werror=format-security -D_FORTIFY_SOURCE=2' \
--with-ld-opt='-Wl,-Bsymbolic-functions -Wl,-z,relro' \
--prefix=/usr/share/nginx \
--conf-path=/etc/nginx/nginx.conf \
--http-log-path=/var/log/nginx/access.log \
--error-log-path=/var/log/nginx/error.log \
--lock-path=/var/lock/nginx.lock \
--pid-path=/run/nginx.pid \
--http-client-body-temp-path=/var/lib/nginx/body \
--http-fastcgi-temp-path=/var/lib/nginx/fastcgi \
--http-proxy-temp-path=/var/lib/nginx/proxy \
--http-scgi-temp-path=/var/lib/nginx/scgi \
--http-uwsgi-temp-path=/var/lib/nginx/uwsgi \
--with-debug \
--with-pcre-jit \
--with-ipv6 \
--with-http_ssl_module \
--with-http_stub_status_module \
--with-http_realip_module \
--with-http_addition_module \
--with-http_dav_module \
--with-http_geoip_module \
--with-http_gzip_static_module \
--with-http_image_filter_module \
--with-http_spdy_module \
--with-http_sub_module \
--with-http_xslt_module \
--with-mail \
--with-mail_ssl_module \
--add-module=../ngx_http_google_filter_module \
--add-module=../ngx_http_substitutions_filter_module # # 覆盖二进制文件 # cp -rf objs/nginx /usr/sbin/nginx # # 重启 nginx 至此, 迁移工作结束 # service nginx stop
service nginx start # # 配置修改后, 需要 restart nginx 来让配置生效 # service nginx restart
基本配置方法
http配置方式
server { server_name <你的域名>; listen 80; resolver 8.8.8.8; location / { google on;
}
}
https配置方式
server { server_name <你的域名>; listen 443; ssl on; ssl_certificate <你的证书>; ssl_certificate_key <你的私钥>; resolver 8.8.8.8; location / { google on;
}
}
进阶配置方法
基本搜索
需要配置 resolver 用于域名解析
server { # ... 仅列举部分配置 resolver 8.8.8.8; location / { google on;
} # ... }
谷歌学术
google_scholar 依赖于 google, 所以 google_scholar 无法独立使用.
由于谷歌学术近日升级, 强制使用 https 协议, 并且 ncr 已经支持, 所以不再需要指定谷歌学术的 tld
配置 nginx
location / { google on; google_scholar on;
}
默认语言偏好
默认的语言偏好可用 google_language 来设置, 如果没有设置, 默认使用 zh-CN (中文)
location / { google on; google_scholar on; # 设置成德文 google_language "de";
}
支持的语言如下.
ar -> 阿拉伯
bg -> 保加利亚
ca -> 加泰罗尼亚
zh-CN -> 中国 (简体)
zh-TW -> 中国 (繁体)
hr -> 克罗地亚
cs -> 捷克
da -> 丹麦
nl -> 荷兰
en -> 英语
tl -> 菲律宾
fi -> 芬兰
fr -> 法国
de -> 德国
el -> 希腊
iw -> 希伯来
hi -> 印地文
hu -> 匈牙利
id -> 印度尼西亚
it -> 意大利
ja -> 日本
ko -> 朝鲜
lv -> 拉脱维亚
lt -> 立陶宛
no -> 挪威
fa -> 波斯
pl -> 波兰
pt-BR -> 葡萄牙 (巴西)
pt-PT -> 葡萄牙 (葡萄牙)
ro -> 罗马尼亚
ru -> 俄罗斯
sr -> 塞尔维亚
sk -> 斯洛伐克
sl -> 斯洛文尼亚
es -> 西班牙
sv -> 瑞典
th -> 泰国
tr -> 土耳其
uk -> 乌克兰
vi -> 越南
搜索引擎爬虫许可
任何搜索引擎爬虫都不被允许爬取 google 镜像
如下的默认 robots.txt 已经内置.
User-agent: *
Disallow: /
如果想要使用 google 自己的 robots.txt 请将 google_robots_allow 设为 on
#... location / { google on; google_robots_allow on;
} #...
Upstreaming
upstream 减少一次域名解析的开销, 并且通过配置多个网段的 google ip 能够一定程度上减少被 google 机器人识别程序侦测到的几率 (弹验证码).
# 可以通过如下方法获取 google ip ➜ ~ dig www.google.com @8.8.8.8 +short
173.194.38.209
173.194.38.211
173.194.38.212
173.194.38.210
173.194.38.208
然后将获取到的 ip 配置如下即可
upstream www.google.com { server 173.194.38.209:443; server 173.194.38.211:443; server 173.194.38.212:443; server 173.194.38.210:443; server 173.194.38.208:443;
}
Proxy Protocal
默认采用 https 与后端服务器通信.
你可以使用 google_ssl_off 来强制将一些域降到 http 协议.
这个设置可以让一些需要二次转发的域通过 http 协议进行转发, 从而不再依赖 ssl 证书.
https://github.com/cuber/ngx_http_google_filter_module/blob/master/README.zh-CN.md
https://github.com/cuber/ngx_http_google_filter_module/blob/master/README.md