查看所有用户下的定时任务
for u in `cat /etc/passwd | cut -d":" -f1`;do crontab -l -u $u;done
更简单是是
cat /var/spool/cron/*
查看所有用户下的定时任务
for u in `cat /etc/passwd | cut -d":" -f1`;do crontab -l -u $u;done
更简单是是
cat /var/spool/cron/*
Redis服务器设置密码后,使用/etc/init.d/redis restart出现(error) NOAUTH Authentication required.
#/etc/init.d/redis restart
Stopping …
可以使用ps -ef | grep redis 查进程号 然后kill 掉,如果在deamon下还需要去删除pid文件,有点繁琐。
解决办法:
用redis-cli 密码登陆(redis-cli -a password)就OK了。
再用ps -ef | grep redis 可以看到redis进程已经正常退出。
修改redis服务脚本,加入如下所示的红色授权信息即可:
1. sqlite3 dbName.sqlite3 加载数据库,不存载就创建
2. .help 帮助详解
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
sqlite> .help
.backup ?DB? FILE Backup DB (default "main") to FILE
.bail ON|OFF Stop after hitting an error. Default OFF
.databases List names and files of attached databases
.dump ?TABLE? ... Dump the database in an SQL text format
If TABLE specified, only dump tables matching
LIKE pattern TABLE.
.echo ON|OFF Turn command echo on or off
.exit Exit this program
.explain ?ON|OFF? Turn output mode suitable for EXPLAIN on or off.
With no args, it turns EXPLAIN on.
.header(s) ON|OFF Turn display of headers on or off
.help Show this message
.import FILE TABLE Import data from FILE into TABLE
.indices ?TABLE? Show names of all indices
If TABLE specified, only show indices for tables
matching LIKE pattern TABLE.
.load FILE ?ENTRY? Load an extension library
.log FILE|off Turn logging on or off. FILE can be stderr/stdout
.mode MODE ?TABLE? Set output mode where MODE is one of:
csv Comma-separated values
column Left-aligned columns. (See .width)
html HTML <table> code
insert SQL insert statements for TABLE
line One value per line
list Values delimited by .separator string
tabs Tab-separated values
tcl TCL list elements
.nullvalue STRING Print STRING in place of NULL values
.output FILENAME Send output to FILENAME
.output stdout Send output to the screen
.prompt MAIN CONTINUE Replace the standard prompts
.quit Exit this program
.read FILENAME Execute SQL in FILENAME
.restore ?DB? FILE Restore content of DB (default "main") from FILE
.schema ?TABLE? Show the CREATE statements
If TABLE specified, only show tables matching
LIKE pattern TABLE.
.separator STRING Change separator used by output mode and .import
.show Show the current values for various settings
.stats ON|OFF Turn stats on or off
.tables ?TABLE? List names of tables
If TABLE specified, only list tables matching
LIKE pattern TABLE.
.timeout MS Try opening locked tables for MS milliseconds
.width NUM1 NUM2 ... Set column widths for "column" mode
.timer ON|OFF Turn the CPU timer measurement on or off
|
3. 应用截图
加载
root@ubuntu:~/workspace/SVN_AUTH/db# sqlite3 development.sqlite3
SQLite version 3.7.2
Enter ".help" for instructions
Enter SQL statements terminated with a ";"
|
显示数据库
|
1
2
3
4
|
sqlite> .databases
seq name file
--- --------------- ----------------------------------------------------------
0 main /root/workspace/SVN_AUTH/db/development.sqlite3
|
显示表
sqlite> .tables
applies logs repositories users
deps permits schema_migrations
|
显示表的内容
sqlite> .head on #显示表头
sqlite> select * from users;
id|name|brief|group|dep_id|created_at|updated_at
1|3B-7-1-16 刘文民|liuwm|superadmin||2011-08-08 08:11:37.283136|2011-08-08 08:11:37.283136
3|3D-1-01 贾延平|jiayp|admin||2011-08-08 08:19:51.745947|2011-08-08 08:19:51.745947
4|3B-7-1-11 杜宏伟|duhw|||2011-08-08 08:33:51.496746|2011-08-08 08:33:51.496746
5|3B-2-14 苑辰|yuanc-a|emplooyee||2011-08-08 08:52:03.229173|2011-08-08 08:52:03.229173
6|3B-2-16 周四维|zhousw|||2011-08-08 08:54:21.134175|2011-08-08 08:54:21.134175
7|3B-2-12 施晟|shis|||2011-08-08 08:56:01.234077|2011-08-08 08:56:01.234077
|
显示创建表的脚本(不跟参数显示所有的)
数据导入的来源可以是其他应用程序的输出,也可以是指定的文本文件,这里采用指定的文本文件。
1. 首先,确定导入的数据源,这里是待导入的,按固定格式的文本文件。
2. 然后,依照导入的文件格式,确定想导入的目标数据表,这个数据表如果没有,可以依照待导入的文本文件格式,创建一个相对应的数据表。
3. 最后,执行.import命令,将文本文件中数据导入数据表中。
1. 数据源
在/home/ywx/yu/sqlite/下,创建一个名为data.txt的文本文件,并输入以下数据,数据之间采用逗号隔开
2. 目标数据表
这里创建一张目标数据表,通过分析文本格式,这里需要3个字段,分别是id,name,age。但在数据类型选择时存在一个问题,id和age在文本文件中是按字符型存储的,而其实际在数据表中,最好要表示成整型,因此这里要涉及到一个字符型数据类型向整型数据类型转换的问题。
在创建表时,将id和age的类型定义为整型,进行强制转换,如果在数据导入时,发现转换失败,可以将id和age类型改为文本型。
3. 导入命令
这里需要注意一点,在数据导入之前,先要根据数据的具体分的格式,设置数据导入的间隔符,例如在文本数据中采用的是‘,’来间隔数据,因此应先调用.seperator 设置‘,’ 为间隔符。
2. 查看命令
.schema 命令来查看指定的数据表的结构
2. .tables 命令用来查看当前数据库的所有数据表
3. databases 命令用来查看当前所有数据库
3. 数据导出
数据导出也是一个常用到的操作,可以将指定表中的数据导出成SQL脚本,供其他数据库使用,还可以将指定的数据表中的数据完整定位到标准输出,也可以将指定数据库中的数据完整的导入到另一个指定数据库等,
1. 导出成指定的SQL脚本
将sqlite中指定的数据表以SQL创建脚本的形式导出,具体命令
2. 数据库导出
3. 其他格式,如:htm格式输出
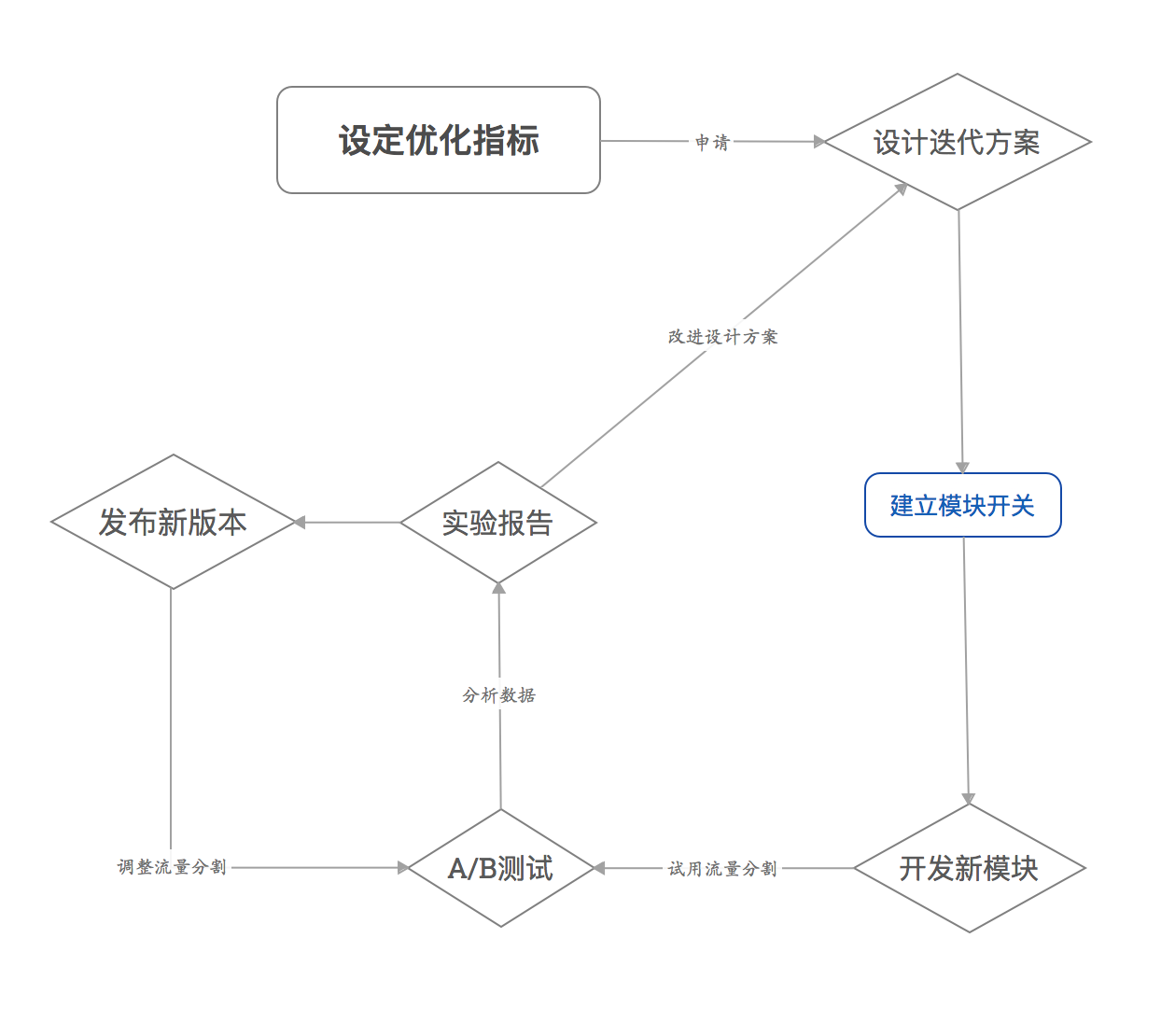
灰度发布是指在黑与白之间,能够平滑过渡的一种发布方式。AB test就是一种灰度发布方式,让一部分用户继续用A,一部分用户开始用B,如果用户对B没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到B上面来。
灰度发布可以保证整体系统的稳定,在初始灰度的时候就可以发现、调整问题,以保证其影响度。
灰度发布常见一般有三种方式:
本文主要将讲解根据Cookie和来路IP这两种方式实现简单的灰度发布,Nginx+LUA这种方式涉及内容太多就不再本文展开了。
A/B测试流程
根据Cookie查询Cookie键为version的值,如果该Cookie值为V1则转发到hilinux_01,为V2则转发到hilinux_02。Cookie值都不匹配的情况下默认走hilinux_01所对应的服务器。
两台服务器分别定义为:
1 2 |
hilinux_01 192.168.1.100:8080 hilinux_02 192.168.1.200:8080 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
upstream hilinux_01 { server 192.168.1.100:8080 max_fails=1 fail_timeout=60; } upstream hilinux_02 { server 192.168.1.200:8080 max_fails=1 fail_timeout=60; } upstream default { server 192.168.1.100:8080 max_fails=1 fail_timeout=60; } server { listen 80; server_name www.hi-linux.com; access_log logs/www.hi-linux.com.log main; #match cookie set $group "default"; if ($http_cookie ~* "version=V1"){ set $group hilinux_01; } if ($http_cookie ~* "version=V2"){ set $group hilinux_02; } location / { proxy_pass http://$group; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; index index.html index.htm; } } |
在Nginx里面配置一个映射,$COOKIE_version可以解析出Cookie里面的version字段。$group是一个变量,{}里面是映射规则。
如果一个version为V1的用户来访问,$group就等于hilinux_01。在server里面使用就会代理到http://hilinux_01上。version为V2的用户来访问,$group就等于hilinux_02。在server里面使用就会代理到http://hilinux_02上。Cookie值都不匹配的情况下默认走hilinux_01所对应的服务器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
upstream hilinux_01 { server 192.168.1.100:8080 max_fails=1 fail_timeout=60; } upstream hilinux_02 { server 192.168.1.200:8080 max_fails=1 fail_timeout=60; } upstream default { server 192.168.1.100:8080 max_fails=1 fail_timeout=60; } map $COOKIE_version $group { ~*V1$ hilinux_01; ~*V2$ hilinux_02; default default; } server { listen 80; server_name www.hi-linux.com; access_log logs/www.hi-linux.com.log main; location / { proxy_pass http://$group; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; index index.html index.htm; } } |
如果是内部IP,则反向代理到hilinux_02(预发布环境);如果不是则反向代理到hilinux_01(生产环境)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
upstream hilinux_01 { server 192.168.1.100:8080 max_fails=1 fail_timeout=60; } upstream hilinux_02 { server 192.168.1.200:8080 max_fails=1 fail_timeout=60; } upstream default { server 192.168.1.100:8080 max_fails=1 fail_timeout=60; } server { listen 80; server_name www.hi-linux.com; access_log logs/www.hi-linux.com.log main; set $group default; if ($remote_addr ~ "211.118.119.11") { set $group hilinux_02; } location / { proxy_pass http://$group; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; index index.html index.htm; } } |
如果你只有单台服务器,可以根据不同的IP设置不同的网站根目录来达到相同的目的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
server { listen 80; server_name www.hi-linux.com; access_log logs/www.hi-linux.com.log main; set $rootdir "/var/www/html"; if ($remote_addr ~ "211.118.119.11") { set $rootdir "/var/www/test"; } location / { root $rootdir; } } |
到此最基本的实现灰度发布方法就讲解完了,如果要做更细粒度灰度发布可参考ABTestingGateway项目。
ABTestingGateway是新浪开源的一个动态路由系统。ABTestingGateway是一个可以动态设置分流策略的灰度发布系统,工作在7层,基于nginx和ngx-lua开发,使用redis作为分流策略数据库,可以实现动态调度功能。
ABTestingGateway:https://github.com/CNSRE/ABTestingGateway
https://www.hi-linux.com/posts/34319.html
wKioL1mKiFzyAHTYAAZzy5AQiS4317.jpg
二,排查
1,发现系统没有任何负载
2,网卡也没有丢包
3,iptables策略也都没问题
4,系统的SYN_RECV连接很少,也没超限
5,系统的文件描述符等资源也都没问题
6,messages和dmesg中没有任何提示或者错误信息
7,通过netstat命令查看系统上协议统计信息,发现很多请求由于时间戳的问题被rejected
# netstat -s |grep reject
2181 passive connections rejected because of time stamp
34 packets rejects in established connections because of timestamp
三,通过google来协助
发现有同样的人遇见这个问题:
是通过调整sysctl -w net.ipv4.tcp_timestamps=0或者sysctl -w net.ipv4.tcp_tw_recycle=0来解决这个问题,于是我就顺藤摸瓜继续查。
而在查询这两个参数的过程中,发现问题原因如下:
发现是 Linux tcp_tw_recycle/tcp_timestamps设置导致的问题。 因为在linux kernel源码中发现tcp_tw_recycle/tcp_timestamps都开启的条件下,60s内同一源ip主机的socket connect请求中的timestamp必须是递增的。经过测试,我这边centos6系统(kernel 2.6.32)和centos7系统(kernel 3.10.0)都有这问题。
源码函数:kernel 2.6.32 tcp_v4_conn_request(),该函数是tcp层三次握手syn包的处理函数(服务端);
源码片段:
if (tmp_opt.saw_tstamp &&
tcp_death_row.sysctl_tw_recycle &&
(dst = inet_csk_route_req(sk, req)) != NULL &&
(peer = rt_get_peer((struct rtable *)dst)) != NULL &&
peer->v4daddr == saddr) {
if (get_seconds() < peer->tcp_ts_stamp + TCP_PAWS_MSL &&
(s32)(peer->tcp_ts – req->ts_recent) >
TCP_PAWS_WINDOW) {
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_PAWSPASSIVEREJECTED);
goto drop_and_release;
}
}
tmp_opt.saw_tstamp:该socket支持tcp_timestamp
sysctl_tw_recycle:本机系统开启tcp_tw_recycle选项
TCP_PAWS_MSL:60s,该条件判断表示该源ip的上次tcp通讯发生在60s内
TCP_PAWS_WINDOW:1,该条件判断表示该源ip的上次tcp通讯的timestamp 大于 本次tcp
总结:
我这边和其它同事通过公司出口(NAT网关只有1个ip地址)访问问题server,由于timestamp时间为系统启动到当前的时间,故我和其它同事的timestamp肯定不相同;根据上述SYN包处理源码,在tcp_tw_recycle和tcp_timestamps同时开启的条件下,timestamp大的主机访问serverN成功,而timestmap小的主机访问失败。并且,我在办公网找了两台机器可100%重现这个问题。
解决:
# echo “0” > /proc/sys/net/ipv4/tcp_tw_recycle
四,扩展
1,net.ipv4.tcp_timestamps
tcp_timestamps的本质是记录数据包的发送时间。基本的步骤如下:
发送方在发送数据时,将一个timestamp(表示发送时间)放在包里面
接收方在收到数据包后,在对应的ACK包中将收到的timestamp返回给发送方(echo back)
发送发收到ACK包后,用当前时刻now – ACK包中的timestamp就能得到准确的RTT
当然实际运用中要考虑到RTT的波动,因此有了后续的(Round-Trip Time Measurement)RTTM机制。
TCP Timestamps Option (TSopt)具体设计如下
Kind: 8 // 标记唯一的选项类型,比如window scale是3
Length: 10 bytes // 标记Timestamps选项的字节数
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| Kind=8 | Length=10 | TS Value (TSval) | TS ECho Reply (TSecr) |
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
1 1 4 4
timestamps一个双向的选项,当一方不开启时,两方都将停用timestamps。比如client端发送的SYN包中带有timestamp选项,但server端并没有开启该选项。则回复的SYN-ACK将不带timestamp选项,同时client后续回复的ACK也不会带有timestamp选项。当然,如果client发送的SYN包中就不带timestamp,双向都将停用timestamp。
tcp数据包中timestamps的value是系统开机时间到现在时间的(毫秒级)时间戳。
参数:
0:停用
1:启用(系统默认值)
2,net.ipv4.tcp_tw_recycle
TCP规范中规定的处于TIME_WAIT的TCP连接必须等待2MSL时间。但在linux中,如果开启了tcp_tw_recycle,TIME_WAIT的TCP连接就不会等待2MSL时间(而是rto或者60s),从而达到快速重用(回收)处于TIME_WAIT状态的tcp连接的目的。这就可能导致连接收到之前连接的数据。为此,linux在打开tcp_tw_recycle的情况下,会记录下TIME_WAIT连接的对端(peer)信息,包括IP地址、时间戳等。这样,当内核收到同一个IP的SYN包时,就会去比较时间戳,检查SYN包的时间戳是否滞后,如果滞后,就将其丢掉(认为是旧连接的数据)。这在绝大部分情况下是没有问题的,但是对于我们实际的client-server的服务,访问我们服务的用户一般都位于NAT之后,如果NAT之后有多个用户访问同一个服务,就有可能因为时间戳滞后的连接被丢掉。
参数:
0:停用(系统默认值)
1:启用
参考:
https://serverfault.com/questions/235965/why-would-a-server-not-send-a-syn-ack-packet-in-response-to-a-syn-packet
http://hustcat.github.io/tcp_tw_recycle-and-tcp_timestamp/
free工具用来查看系统可用内存:
/opt/app/tdev1$free
total used free shared buffers cached
Mem: 8175320 6159248 2016072 0 310208 5243680
-/+ buffers/cache: 605360 7569960
Swap: 6881272 16196 6865076
解释一下Linux上free命令的输出。
下面是free的运行结果,一共有4行。为了方便说明,我加上了列号。这样可以把free的输出看成一个二维数组FO(Free Output)。例如:
FO[2][1] = 24677460 FO[3][2] = 10321516 1 2 3 4 5 6 1 total used free shared buffers cached 2 Mem: 24677460 23276064 1401396 0 870540 12084008 3 -/+ buffers/cache: 10321516 14355944 4 Swap: 25151484 224188 24927296
free的输出一共有四行,第四行为交换区的信息,分别是交换的总量(total),使用量(used)和有多少空闲的交换区(free),这个比较清楚,不说太多。
free输出地第二行和第三行是比较让人迷惑的。这两行都是说明内存使用情况的。第一列是总量(total),第二列是使用量(used),第三列是可用量(free)。
第一行的输出时从操作系统(OS)来看的。也就是说,从OS的角度来看,计算机上一共有:
24677460KB(缺省时free的单位为KB)物理内存,即FO[2][1]; 在这些物理内存中有23276064KB(即FO[2][2])被使用了; 还用1401396KB(即FO[2][3])是可用的;
这里得到第一个等式:
FO[2][1] = FO[2][2] + FO[2][3]
FO[2][4]表示被几个进程共享的内存的,现在已经deprecated,其值总是0(当然在一些系统上也可能不是0,主要取决于free命令是怎么实现的)。
FO[2][5]表示被OS buffer住的内存。FO[2][6]表示被OS cache的内存。在有些时候buffer和cache这两个词经常混用。不过在一些比较低层的软件里是要区分这两个词的,看老外的洋文:
A buffer is something that has yet to be "written" to disk. A cache is something that has been "read" from the disk and stored for later use.
也就是说buffer是用于存放要输出到disk(块设备)的数据的,而cache是存放从disk上读出的数据。这二者是为了提高IO性能的,并由OS管理。
Linux和其他成熟的操作系统(例如windows),为了提高IO read的性能,总是要多cache一些数据,这也就是为什么FO[2][6](cached memory)比较大,而FO[2][3]比较小的原因。我们可以做一个简单的测试:
释放掉被系统cache占用的数据:
echo 3>/proc/sys/vm/drop_caches
第二次读应该比第一次快很多。原来我做过一个BerkeleyDB的读操作,大概要读5G的文件,几千万条记录。在我的环境上,第二次读比第一次大概可以快9倍左右。
free输出的第二行是从一个应用程序的角度看系统内存的使用情况。
因为被系统cache和buffer占用的内存可以被快速回收,所以通常FO[3][3]比FO[2][3]会大很多。
这里还用两个等式:
FO[3][2] = FO[2][2] - FO[2][5] - FO[2][6] FO[3][3] = FO[2][3] + FO[2][5] + FO[2][6]
这二者都不难理解。
free命令由procps.*.rpm提供(在Redhat系列的OS上)。free命令的所有输出值都是从/proc/meminfo中读出的。
在系统上可能有meminfo(2)这个函数,它就是为了解析/proc/meminfo的。procps这个包自己实现了meminfo()这个函数。可以下载一个procps的tar包看看具体实现,现在最新版式3.2.8。
文章出处:
http://www.cnblogs.com/coldplayerest/archive/2010/02/20/1669949.html
free命令可以显示Linux系统中空闲的、已用的物理内存及swap内存,及被内核使用的buffer。在Linux系统监控的工具中,free命令是最经常使用的命令之一。
1.命令格式:
free [参数]
2.命令功能:
free 命令显示系统使用和空闲的内存情况,包括物理内存、交互区内存(swap)和内核缓冲区内存。共享内存将被忽略
3.命令参数:
-b 以Byte为单位显示内存使用情况。
-k 以KB为单位显示内存使用情况。
-m 以MB为单位显示内存使用情况。
-g 以GB为单位显示内存使用情况。
-o 不显示缓冲区调节列。
-s<间隔秒数> 持续观察内存使用状况。
-t 显示内存总和列。
-V 显示版本信息。
4.使用实例:
实例1:显示内存使用情况
命令:
free
free -g
free –m
输出:
[root@SF1150 service]# free
total used free shared buffers cached
Mem: 32940112 30841684 2098428 0 4545340 11363424
-/+ buffers/cache: 14932920 18007192
Swap: 32764556 1944984 30819572
[root@SF1150 service]# free -g
total used free shared buffers cached
Mem: 31 29 2 0 4 10
-/+ buffers/cache: 14 17
Swap: 31 1 29
[root@SF1150 service]# free -m
total used free shared buffers cached
Mem: 32168 30119 2048 0 4438 11097
-/+ buffers/cache: 14583 17584
Swap: 31996 1899 30097
说明:
下面是对这些数值的解释:
total:总计物理内存的大小。
used:已使用多大。
free:可用有多少。
Shared:多个进程共享的内存总额。
Buffers/cached:磁盘缓存的大小。
第三行(-/+ buffers/cached):
used:已使用多大。
free:可用有多少。
第四行是交换分区SWAP的,也就是我们通常所说的虚拟内存。
区别:第二行(mem)的used/free与第三行(-/+ buffers/cache) used/free的区别。 这两个的区别在于使用的角度来看,第一行是从OS的角度来看,因为对于OS,buffers/cached 都是属于被使用,所以他的可用内存是2098428KB,已用内存是30841684KB,其中包括,内核(OS)使用+Application(X, oracle,etc)使用的+buffers+cached.
第三行所指的是从应用程序角度来看,对于应用程序来说,buffers/cached 是等于可用的,因为buffer/cached是为了提高文件读取的性能,当应用程序需在用到内存的时候,buffer/cached会很快地被回收。
所以从应用程序的角度来说,可用内存=系统free memory+buffers+cached。
如本机情况的可用内存为:
18007156=2098428KB+4545340KB+11363424KB
接下来解释什么时候内存会被交换,以及按什么方交换。
当可用内存少于额定值的时候,就会开会进行交换.如何看额定值:
命令:
cat /proc/meminfo
输出:
[root@SF1150 service]# cat /proc/meminfo
MemTotal: 32940112 kB
MemFree: 2096700 kB
Buffers: 4545340 kB
Cached: 11364056 kB
SwapCached: 1896080 kB
Active: 22739776 kB
Inactive: 7427836 kB
HighTotal: 0 kB
HighFree: 0 kB
LowTotal: 32940112 kB
LowFree: 2096700 kB
SwapTotal: 32764556 kB
SwapFree: 30819572 kB
Dirty: 164 kB
Writeback: 0 kB
AnonPages: 14153592 kB
Mapped: 20748 kB
Slab: 590232 kB
PageTables: 34200 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
CommitLimit: 49234612 kB
Committed_AS: 23247544 kB
VmallocTotal: 34359738367 kB
VmallocUsed: 278840 kB
VmallocChunk: 34359459371 kB
HugePages_Total: 0HugePages_Free: 0HugePages_Rsvd: 0Hugepagesize: 2048 kB
交换将通过三个途径来减少系统中使用的物理页面的个数:
1.减少缓冲与页面cache的大小,
2.将系统V类型的内存页面交换出去,
3.换出或者丢弃页面。(Application 占用的内存页,也就是物理内存不足)。
事实上,少量地使用swap是不是影响到系统性能的。
那buffers和cached都是缓存,两者有什么区别呢?
为了提高磁盘存取效率, Linux做了一些精心的设计, 除了对dentry进行缓存(用于VFS,加速文件路径名到inode的转换), 还采取了两种主要Cache方式:Buffer Cache和Page Cache。前者针对磁盘块的读写,后者针对文件inode的读写。这些Cache有效缩短了 I/O系统调用(比如read,write,getdents)的时间。
磁盘的操作有逻辑级(文件系统)和物理级(磁盘块),这两种Cache就是分别缓存逻辑和物理级数据的。
Page cache实际上是针对文件系统的,是文件的缓存,在文件层面上的数据会缓存到page cache。文件的逻辑层需要映射到实际的物理磁盘,这种映射关系由文件系统来完成。当page cache的数据需要刷新时,page cache中的数据交给buffer cache,因为Buffer Cache就是缓存磁盘块的。但是这种处理在2.6版本的内核之后就变的很简单了,没有真正意义上的cache操作。
Buffer cache是针对磁盘块的缓存,也就是在没有文件系统的情况下,直接对磁盘进行操作的数据会缓存到buffer cache中,例如,文件系统的元数据都会缓存到buffer cache中。
简单说来,page cache用来缓存文件数据,buffer cache用来缓存磁盘数据。在有文件系统的情况下,对文件操作,那么数据会缓存到page cache,如果直接采用dd等工具对磁盘进行读写,那么数据会缓存到buffer cache。
所以我们看linux,只要不用swap的交换空间,就不用担心自己的内存太少.如果常常swap用很多,可能你就要考虑加物理内存了.这也是linux看内存是否够用的标准.
如果是应用服务器的话,一般只看第二行,+buffers/cache,即对应用程序来说free的内存太少了,也是该考虑优化程序或加内存了。
实例2:以总和的形式显示内存的使用信息
命令:
free -t
输出:
[root@SF1150 service]# free -t
total used free shared buffers cached
Mem: 32940112 30845024 2095088 0 4545340 11364324
-/+ buffers/cache: 14935360 18004752Swap: 32764556 1944984 30819572Total: 65704668 32790008 32914660[root@SF1150 service]#
说明:
实例3:周期性的查询内存使用信息
命令:
free -s 10
输出:
[root@SF1150 service]# free -s 10
total used free shared buffers cached
Mem: 32940112 30844528 2095584 0 4545340 11364380
-/+ buffers/cache: 14934808 18005304Swap: 32764556 1944984 30819572
total used free shared buffers cached
Mem: 32940112 30843932 2096180 0 4545340 11364388
-/+ buffers/cache: 14934204 18005908Swap: 32764556 1944984 30819572
说明:
每10s 执行一次命令
https://www.cnblogs.com/peida/archive/2012/12/25/2831814.html
在服务端,连接达到一定数量,诸如50W时,有些隐藏很深的问题,就不断的抛出来。 通过查看dmesg命令查看,发现大量TCP: too many of orphaned sockets错误,也很正常,下面到了需要调整tcp socket参数的时候了。
第一个需要调整的是tcp_rmem,即TCP读取缓冲区,单位为字节,查看默认值
默认值为87380 byte ≈ 86K,最小为4096 byte=4K,最大值为4064K。
第二个需要调整的是tcp_wmem,发送缓冲区,单位是字节,默认值
解释同上
第三个需要调整的tcp_mem,调整TCP的内存大小,其单位是页,1页等于4096字节。系统默认值:
tcp_mem(3个INTEGER变量):low, pressure, high
一般情况下这些值是在系统启动时根据系统内存数量计算得到的。 根据当前tcp_mem最大内存页面数是1864896,当内存为(1864896*4)/1024K=7284.75M时,系统将无法为新的socket连接分配内存,即TCP连接将被拒绝。
实际测试环境中,据观察大概在99万个连接左右的时候(零头不算),进程被杀死,触发out of socket memory错误(dmesg命令查看获得)。每一个连接大致占用7.5K内存(下面给出计算方式),大致可算的此时内存占用情况(990000 * 7.5 / 1024K = 7251M)。
这样和tcp_mem最大页面值数量比较吻合,因此此值也需要修改。
三个TCP调整语句为:
备注: 为了节省内存,设置tcp读、写缓冲区都为4K大小,tcp_mem三个值分别为3G 8G 16G,tcp_rmem和tcp_wmem最大值也是16G。
经过若干次的尝试,最终达到目标,1024000个持久连接。1024000数字是怎么得来的呢,两台物理机器各自发出64000个请求,两个配置为6G左右的centos测试端机器(绑定7个桥接或NAT连接)各自发出640007 = 448000。也就是 1024000 = (64000) + (64000) + (640007) + (64000*7), 共使用了16个网卡(物理网卡+虚拟网卡)。
终端输出
在线用户目标达到1024000个!
服务启动时内存占用:
系统达到1024000个连接后的内存情况(执行三次 free -m 命令,获取三次结果):
这三次内存使用分别是7680,7692,7702,这次不取平均值,取一个中等偏上的值,定为7701M。那么程序接收1024000个连接,共消耗了 7701M-171M = 7530M内存, 7530M*1024K / 1024000 = 7.53K, 每一个连接消耗内存在为7.5K左右,这和在连接达到512000时所计算较为吻合。
虚拟机运行Centos内存占用,不太稳定,但一般相差不大,以上数值,仅供参考。
执行top -p 某刻输出信息:
执行vmstate:
获取当前socket连接状态统计信息:
获取当前系统打开的文件句柄:
此时任何类似于下面查询操作都是一个慢,等待若干时间还不见得执行完毕。
以上两个命令在二三十分钟过去了,还未执行完毕,只好停止。
本次从头到尾的测试,所需要有的linux系统需要调整的参数也就是那么几个,汇总一下:
其它没有调整的参数,仅仅因为它们暂时对本次测试没有带来什么影响,实际环境中需要结合需要调整类似于SO_KEEPALIVE、tcpmax_orphans等大量参数。
[root@2 ~]# time for i in `seq 1 100`;do dig @8.8.8.8 www.alidns.com > /dev/null 2>&1; done
real 0m14.733s
user 0m0.227s
sys 0m0.302s
[root@2 ~]# time for i in `seq 1 100`;do dig @119.29.29.29 www.alidns.com > /dev/null 2>&1; done
real 0m14.249s
user 0m0.224s
sys 0m0.327s
[root@2 ~]# time for i in `seq 1 100`;do dig @114.114.114.114 www.alidns.com > /dev/null 2>&1; done
real 0m14.856s
user 0m0.235s
sys 0m0.312s
[root@2 ~]# time for i in `seq 1 100`;do dig @223.5.5.5 www.alidns.com > /dev/null 2>&1; done
real 0m13.729s
user 0m0.235s
sys 0m0.309s
[root@2 ~]# time for i in `seq 1 100`;do dig @180.76.76.76 www.alidns.com > /dev/null 2>&1; done
real 1m8.154s
user 0m0.205s
sys 0m0.326s
[root@2 ~]# time for i in `seq 1 100`;do dig @101.226.4.6 www.alidns.com > /dev/null 2>&1; done
real 0m16.814s
user 0m0.225s
sys 0m0.307s
[root@2 ~]# time for i in `seq 1 100`;do dig @1.2.4.8 www.alidns.com > /dev/null 2>&1; done
real 0m14.493s
user 0m0.215s
sys 0m0.317s
[root@2 ~]# time for i in `seq 1 100`;do dig @208.67.222.222 www.alidns.com > /dev/null 2>&1; done
real 0m47.309s
user 0m0.228s
sys 0m0.326s
[root@2 ~]# time for i in `seq 1 100`;do dig @208.67.222.222 www.alidns.com > /dev/null 2>&1; done
c^C
real 1m36.730s
user 0m0.214s
sys 0m0.320s
[root@2 ~]# time for i in `seq 1 100`;do dig @4.2.2.1 www.alidns.com > /dev/null 2>&1; done
real 0m38.440s
user 0m0.224s
sys 0m0.303s
[root@2 ~]# time for i in `seq 1 100`;do dig @1.1.1.1 www.alidns.com > /dev/null 2>&1; done
real 0m27.393s
user 0m0.239s
sys 0m0.292s
阿里公共DNS 223.5.5.5 和 223.6.6.6是阿里巴巴集团推出的DNS递归解析系统,目标是成为国内互联网基础设施的组成部分,面向互联网用户提供“快速”、“稳定”、“智能”的免费DNS递归解析服务
通过批量测试发现,223.5.5.5 和 223.6.6.6解析不常用域名超慢,达到2-6秒甚至超时解析。这个不知道阿里DNS是什么时候改的,同样对比腾讯119.29.29.29及114DNS 114.114.114.114 及google DNS 8.8.8.8没有这个问题。
批量测试100次,看看返回结果时间:
[root@2 ~]# time for i in `seq 1 100`;do dig @223.6.6.6 www.dnsdizhi.com +short > /dev/null 2>&1; done
real 0m51.319s
user 0m0.215s
sys 0m0.316s
[root@2 ~]# time for i in `seq 1 100`;do dig @223.6.6.6 www.dnsdizhi.com +short > /dev/null 2>&1; done
real 0m3.533s
user 0m0.194s
sys 0m0.346s
[root@2 ~]# time for i in `seq 1 100`;do dig @223.6.6.6 www.dnsdizhi.com +short > /dev/null 2>&1; done
real 0m1.161s
user 0m0.221s
sys 0m0.328s
[root@2 ~]# time for i in `seq 1 100`;do dig @223.6.6.6 www.dnsdizhi.com +short > /dev/null 2>&1; done
real 0m1.135s
user 0m0.210s
sys 0m0.308s
第一个100次,需要51秒,而后面都非常快。
我们详细看看前100次域名解析耗时情况:
第1-10次:
[root@2 ~]# time for i in `seq 1 10`;do time dig @223.6.6.6 www.dnsdizhi.com +short; done
119.28.12.243
real 0m1.134s
user 0m0.004s
sys 0m0.002s
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.68.rc1.el6_10.1 <<>> @223.6.6.6 www.dnsdizhi.com +short
; (1 server found)
;; global options: +cmd
;; connection timed out; no servers could be reached
real 0m6.005s
user 0m0.002s
sys 0m0.003s
119.28.12.243
real 0m0.032s
user 0m0.003s
sys 0m0.003s
119.28.12.243
real 0m2.072s
user 0m0.003s
sys 0m0.002s
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.68.rc1.el6_10.1 <<>> @223.6.6.6 www.dnsdizhi.com +short
; (1 server found)
;; global options: +cmd
;; connection timed out; no servers could be reached
real 0m6.005s
user 0m0.001s
sys 0m0.004s
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.68.rc1.el6_10.1 <<>> @223.6.6.6 www.dnsdizhi.com +short
; (1 server found)
;; global options: +cmd
;; connection timed out; no servers could be reached
real 0m6.006s
user 0m0.003s
sys 0m0.003s
119.28.12.243
real 0m0.009s
user 0m0.001s
sys 0m0.004s
119.28.12.243
real 0m0.037s
user 0m0.002s
sys 0m0.003s
119.28.12.243
real 0m2.032s
user 0m0.002s
sys 0m0.001s
119.28.12.243
real 0m0.012s
user 0m0.002s
sys 0m0.003s
real 0m23.347s
user 0m0.023s
sys 0m0.029s
第11-20次
[root@2 ~]# time for i in `seq 1 10`;do time dig @223.6.6.6 www.dnsdizhi.com +short; done
119.28.12.243
real 0m0.009s
user 0m0.003s
sys 0m0.003s
119.28.12.243
real 0m4.031s
user 0m0.003s
sys 0m0.002s
119.28.12.243
real 0m4.032s
user 0m0.002s
sys 0m0.003s
119.28.12.243
real 0m0.013s
user 0m0.004s
sys 0m0.002s
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.68.rc1.el6_10.1 <<>> @223.6.6.6 www.dnsdizhi.com +short
; (1 server found)
;; global options: +cmd
;; connection timed out; no servers could be reached
real 0m6.005s
user 0m0.003s
sys 0m0.002s
119.28.12.243
real 0m0.032s
user 0m0.004s
sys 0m0.002s
119.28.12.243
real 0m0.011s
user 0m0.000s
sys 0m0.005s
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.68.rc1.el6_10.1 <<>> @223.6.6.6 www.dnsdizhi.com +short
; (1 server found)
;; global options: +cmd
;; connection timed out; no servers could be reached
real 0m6.005s
user 0m0.002s
sys 0m0.003s
119.28.12.243
real 0m0.012s
user 0m0.004s
sys 0m0.002s
119.28.12.243
real 0m4.045s
user 0m0.000s
sys 0m0.005s
real 0m24.198s
user 0m0.026s
sys 0m0.029s
第21-30次
[root@2 ~]# time for i in `seq 1 10`;do time dig @223.6.6.6 www.dnsdizhi.com +short; done
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.68.rc1.el6_10.1 <<>> @223.6.6.6 www.dnsdizhi.com +short
; (1 server found)
;; global options: +cmd
;; connection timed out; no servers could be reached
real 0m6.006s
user 0m0.002s
sys 0m0.003s
119.28.12.243
real 0m0.009s
user 0m0.003s
sys 0m0.003s
119.28.12.243
real 0m0.023s
user 0m0.003s
sys 0m0.002s
119.28.12.243
real 0m0.014s
user 0m0.004s
sys 0m0.001s
119.28.12.243
real 0m0.016s
user 0m0.002s
sys 0m0.002s
119.28.12.243
real 0m4.039s
user 0m0.002s
sys 0m0.003s
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.68.rc1.el6_10.1 <<>> @223.6.6.6 www.dnsdizhi.com +short
; (1 server found)
;; global options: +cmd
;; connection timed out; no servers could be reached
real 0m6.006s
user 0m0.002s
sys 0m0.004s
119.28.12.243
real 0m0.027s
user 0m0.003s
sys 0m0.002s
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.68.rc1.el6_10.1 <<>> @223.6.6.6 www.dnsdizhi.com +short
; (1 server found)
;; global options: +cmd
;; connection timed out; no servers could be reached
real 0m6.006s
user 0m0.003s
sys 0m0.003s
119.28.12.243
real 0m0.010s
user 0m0.002s
sys 0m0.003s
real 0m22.156s
user 0m0.027s
sys 0m0.026s
第31-40次
[root@2 ~]# time for i in `seq 1 10`;do time dig @223.6.6.6 www.dnsdizhi.com +short; done
119.28.12.243
real 0m0.012s
user 0m0.001s
sys 0m0.004s
119.28.12.243
real 0m4.076s
user 0m0.003s
sys 0m0.003s
119.28.12.243
real 0m2.026s
user 0m0.003s
sys 0m0.002s
119.28.12.243
real 0m0.025s
user 0m0.005s
sys 0m0.001s
119.28.12.243
real 0m0.033s
user 0m0.002s
sys 0m0.002s
119.28.12.243
real 0m0.026s
user 0m0.002s
sys 0m0.003s
119.28.12.243
real 0m2.026s
user 0m0.003s
sys 0m0.003s
119.28.12.243
real 0m0.026s
user 0m0.002s
sys 0m0.003s
119.28.12.243
real 0m0.010s
user 0m0.001s
sys 0m0.005s
119.28.12.243
real 0m0.028s
user 0m0.002s
sys 0m0.003s
real 0m8.291s
user 0m0.025s
sys 0m0.029s
第41-50次
[root@2 ~]# time for i in `seq 1 10`;do time dig @223.6.6.6 www.dnsdizhi.com +short; done
119.28.12.243
real 0m0.009s
user 0m0.003s
sys 0m0.002s
119.28.12.243
real 0m0.011s
user 0m0.001s
sys 0m0.005s
119.28.12.243
real 0m0.010s
user 0m0.001s
sys 0m0.003s
119.28.12.243
real 0m0.009s
user 0m0.001s
sys 0m0.003s
119.28.12.243
real 0m0.012s
user 0m0.002s
sys 0m0.003s
119.28.12.243
real 0m0.012s
user 0m0.001s
sys 0m0.003s
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.68.rc1.el6_10.1 <<>> @223.6.6.6 www.dnsdizhi.com +short
; (1 server found)
;; global options: +cmd
;; connection timed out; no servers could be reached
real 0m6.004s
user 0m0.000s
sys 0m0.004s
119.28.12.243
real 0m0.008s
user 0m0.004s
sys 0m0.002s
119.28.12.243
real 0m0.015s
user 0m0.002s
sys 0m0.002s
119.28.12.243
real 0m0.017s
user 0m0.001s
sys 0m0.004s
real 0m6.109s
user 0m0.017s
sys 0m0.032s
第51-60次
[root@2 ~]# time for i in `seq 1 10`;do time dig @223.6.6.6 www.dnsdizhi.com +short; done
119.28.12.243
real 0m0.017s
user 0m0.001s
sys 0m0.005s
119.28.12.243
real 0m0.020s
user 0m0.002s
sys 0m0.003s
119.28.12.243
real 0m0.013s
user 0m0.003s
sys 0m0.002s
119.28.12.243
real 0m0.013s
user 0m0.000s
sys 0m0.006s
119.28.12.243
real 0m0.011s
user 0m0.004s
sys 0m0.001s
119.28.12.243
real 0m0.014s
user 0m0.003s
sys 0m0.002s
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.68.rc1.el6_10.1 <<>> @223.6.6.6 www.dnsdizhi.com +short
; (1 server found)
;; global options: +cmd
;; connection timed out; no servers could be reached
real 0m6.005s
user 0m0.001s
sys 0m0.004s
119.28.12.243
real 0m0.019s
user 0m0.004s
sys 0m0.001s
119.28.12.243
real 0m0.024s
user 0m0.003s
sys 0m0.003s
119.28.12.243
real 0m0.017s
user 0m0.001s
sys 0m0.003s
real 0m6.155s
user 0m0.022s
sys 0m0.031s
第61-70次
# time for i in `seq 1 10`;do time dig @223.6.6.6 www.dnsdizhi.com +short; done
119.28.12.243
real 0m0.013s
user 0m0.003s
sys 0m0.003s
119.28.12.243
real 0m0.010s
user 0m0.003s
sys 0m0.002s
119.28.12.243
real 0m0.010s
user 0m0.001s
sys 0m0.004s
119.28.12.243
real 0m0.009s
user 0m0.000s
sys 0m0.004s
119.28.12.243
real 0m0.013s
user 0m0.002s
sys 0m0.003s
119.28.12.243
real 0m0.010s
user 0m0.002s
sys 0m0.003s
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.68.rc1.el6_10.1 <<>> @223.6.6.6 www.dnsdizhi.com +short
; (1 server found)
;; global options: +cmd
;; connection timed out; no servers could be reached
real 0m6.005s
user 0m0.000s
sys 0m0.005s
119.28.12.243
real 0m2.047s
user 0m0.003s
sys 0m0.003s
119.28.12.243
real 0m0.009s
user 0m0.003s
sys 0m0.002s
119.28.12.243
real 0m0.013s
user 0m0.002s
sys 0m0.002s
real 0m8.140s
user 0m0.020s
sys 0m0.031s
第71-80次
# time for i in `seq 1 10`;do time dig @223.6.6.6 www.dnsdizhi.com +short; done
119.28.12.243
real 0m0.010s
user 0m0.002s
sys 0m0.003s
119.28.12.243
real 0m0.012s
user 0m0.001s
sys 0m0.003s
119.28.12.243
real 0m0.013s
user 0m0.002s
sys 0m0.004s
119.28.12.243
real 0m0.009s
user 0m0.001s
sys 0m0.003s
119.28.12.243
real 0m0.014s
user 0m0.001s
sys 0m0.003s
119.28.12.243
real 0m0.045s
user 0m0.004s
sys 0m0.002s
119.28.12.243
real 0m0.012s
user 0m0.001s
sys 0m0.003s
119.28.12.243
real 0m0.013s
user 0m0.001s
sys 0m0.004s
119.28.12.243
real 0m0.010s
user 0m0.000s
sys 0m0.005s
119.28.12.243
real 0m0.011s
user 0m0.002s
sys 0m0.003s
real 0m0.151s
user 0m0.017s
sys 0m0.033s
第81-90次
# time for i in `seq 1 10`;do time dig @223.6.6.6 www.dnsdizhi.com +short; done
119.28.12.243
real 0m0.009s
user 0m0.001s
sys 0m0.004s
119.28.12.243
real 0m0.029s
user 0m0.001s
sys 0m0.005s
119.28.12.243
real 0m0.011s
user 0m0.004s
sys 0m0.001s
119.28.12.243
real 0m0.009s
user 0m0.002s
sys 0m0.002s
119.28.12.243
real 0m0.013s
user 0m0.001s
sys 0m0.006s
119.28.12.243
real 0m0.010s
user 0m0.002s
sys 0m0.003s
119.28.12.243
real 0m0.012s
user 0m0.002s
sys 0m0.003s
119.28.12.243
real 0m0.015s
user 0m0.002s
sys 0m0.003s
119.28.12.243
real 0m0.009s
user 0m0.003s
sys 0m0.002s
119.28.12.243
real 0m0.012s
user 0m0.003s
sys 0m0.002s
real 0m0.131s
user 0m0.023s
sys 0m0.031s
第91-100次
# time for i in `seq 1 10`;do time dig @223.6.6.6 www.dnsdizhi.com +short; done
119.28.12.243
real 0m2.072s
user 0m0.000s
sys 0m0.005s
119.28.12.243
real 0m0.031s
user 0m0.002s
sys 0m0.003s
119.28.12.243
real 0m0.064s
user 0m0.004s
sys 0m0.001s
119.28.12.243
real 0m0.070s
user 0m0.004s
sys 0m0.001s
119.28.12.243
real 0m0.069s
user 0m0.003s
sys 0m0.002s
119.28.12.243
real 0m0.050s
user 0m0.002s
sys 0m0.002s
119.28.12.243
real 0m0.052s
user 0m0.004s
sys 0m0.002s
119.28.12.243
real 0m0.046s
user 0m0.001s
sys 0m0.003s
119.28.12.243
real 0m0.055s
user 0m0.002s
sys 0m0.003s
119.28.12.243
real 0m0.087s
user 0m0.002s
sys 0m0.004s
real 0m2.597s
user 0m0.024s
sys 0m0.027s
和任何开源项目一样, Swoole总是在最新的发行版提供最可靠的稳定性和最强的功能, 请尽量保证你使用的是最新版本
访问我们官网的下载页面
pecl install swoole
非内核开发研究之用途, 请下载发布版本的源码编译
cd swoole-src && \
phpize && \
./configure && \
make && sudo make install
编译安装到系统成功后, 需要在php.ini中加入一行extension=swoole.so来启用Swoole扩展
使用例子:
./configure --enable-openssl --enable-sockets
--enable-openssl 或 --with-openssl-dir=DIR
--enable-sockets
--enable-http2
--enable-mysqlnd (需要 mysqlnd, 只是为了支持mysql->escape方法)
⚠️ 如果你要从源码升级, 别忘记在源码目录执行make clean
pecl upgrade swoole
git pull && cd swoole-src && make clean && make && sudo make install
phpize clean && phpize后重新编译